
Google 近日正式宣布推出其最新語言模型的預覽版 —— Gemini 2.5 Flash。此版本標誌著 Google 在模型效率與控制性方面的新進展,特別導入了創新的可控推理功能與 思考預算(Thinking Budget 機制,旨在賦予開發者前所未有的彈性,以便在應用程式的速度、運算成本及輸出品質之間,根據實際需求進行更精確的調校。
相較於之前的版本,Gemini 2.5 Flash 在維持其著稱的高運算效率基礎上,顯著增強了對複雜任務的理解與處理能力。尤其在需要多步驟推理的指令場景下,新模型的準確度獲得了明顯提升。
目前模型已經在 Google AI Studio 與 Gemini App 上開方使用者免費使用,且 Gemini 的網頁版還可以搭配 Canvas 功能使用,直接用來製作或修改一些網頁。
混合式推理與思考預算機制
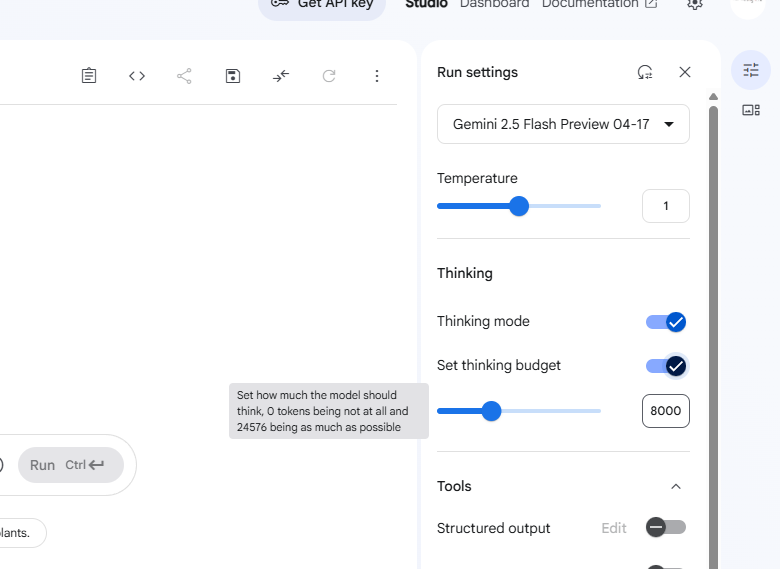
Gemini 2.5 Flash 的核心突破在於其作為 Google 首款混合式推理模型的設計。它引入了創新的可控推理能力與 「思考預算」(Thinking Budget) 機制。開發者現在可以透過 API 或 Google AI Studio 介面,細緻地控制模型的「思考」深度。透過設定 thinking_budget 參數(Token 上限範圍從 0 到 24,576),開發者能為模型的推理過程分配資源預算。系統會智慧地根據輸入提示的複雜度,自動判斷是否需要啟用以及在多大程度上運用推理能力,有效避免了對簡單請求的過度計算。若將預算設為零,模型則會以最低延遲模式運行,快速回應。
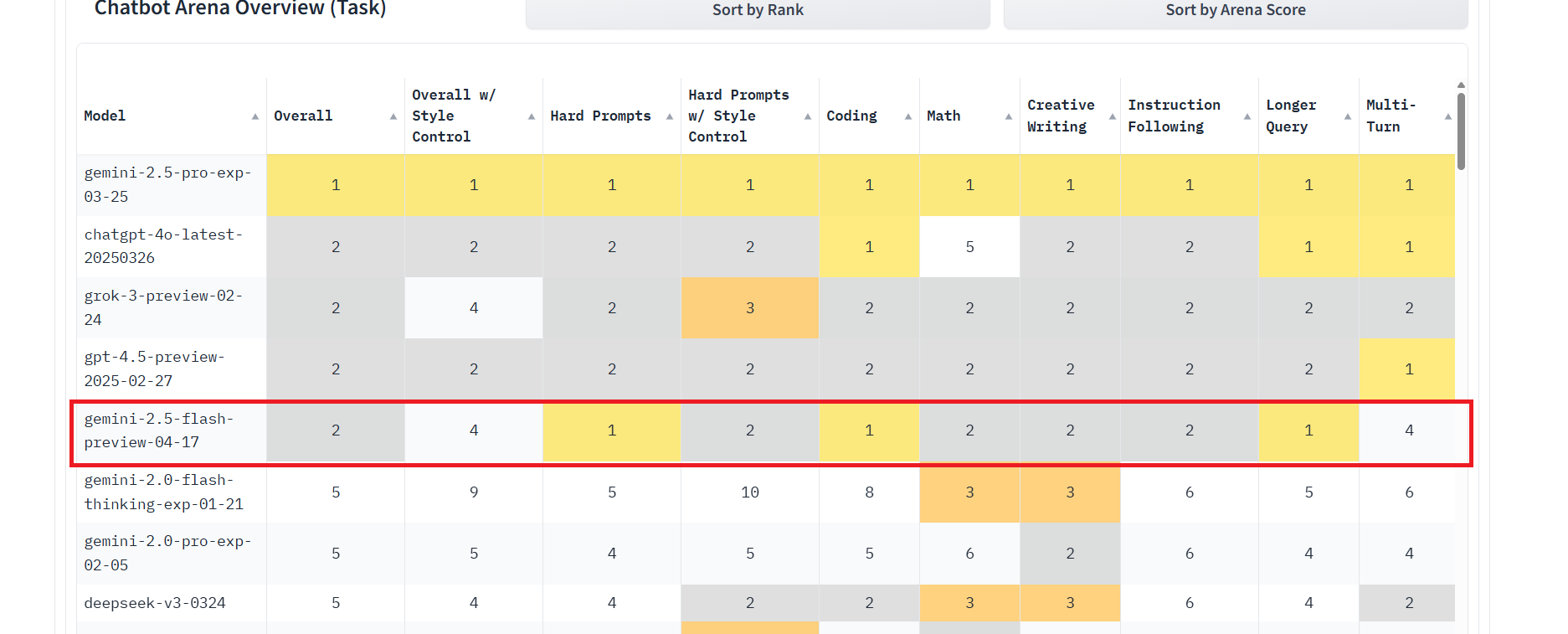
這種架構上的革新直接轉化為顯著的效能提升和更具彈性的成本結構。從 Google 公布的基準測試數據(截至 2025 年 4 月 17 日)來看,Gemini 2.5 Flash 在多個領域展現了令人矚目的進步。例如,在涉及複雜推理的數學(AIME 2025/2024)和科學(GPQA diamond)基準測試中,其 pass@1 分數相較於 Gemini 2.0 Flash 實現了翻倍甚至接近三倍的增長,達到 78% 至 88% 的水平。同樣,在程式碼生成(LiveCodeBench v5)和編輯(Aider Polyglot)任務上,效能也獲得了大幅躍升,分數提高了近 30 個百分點。
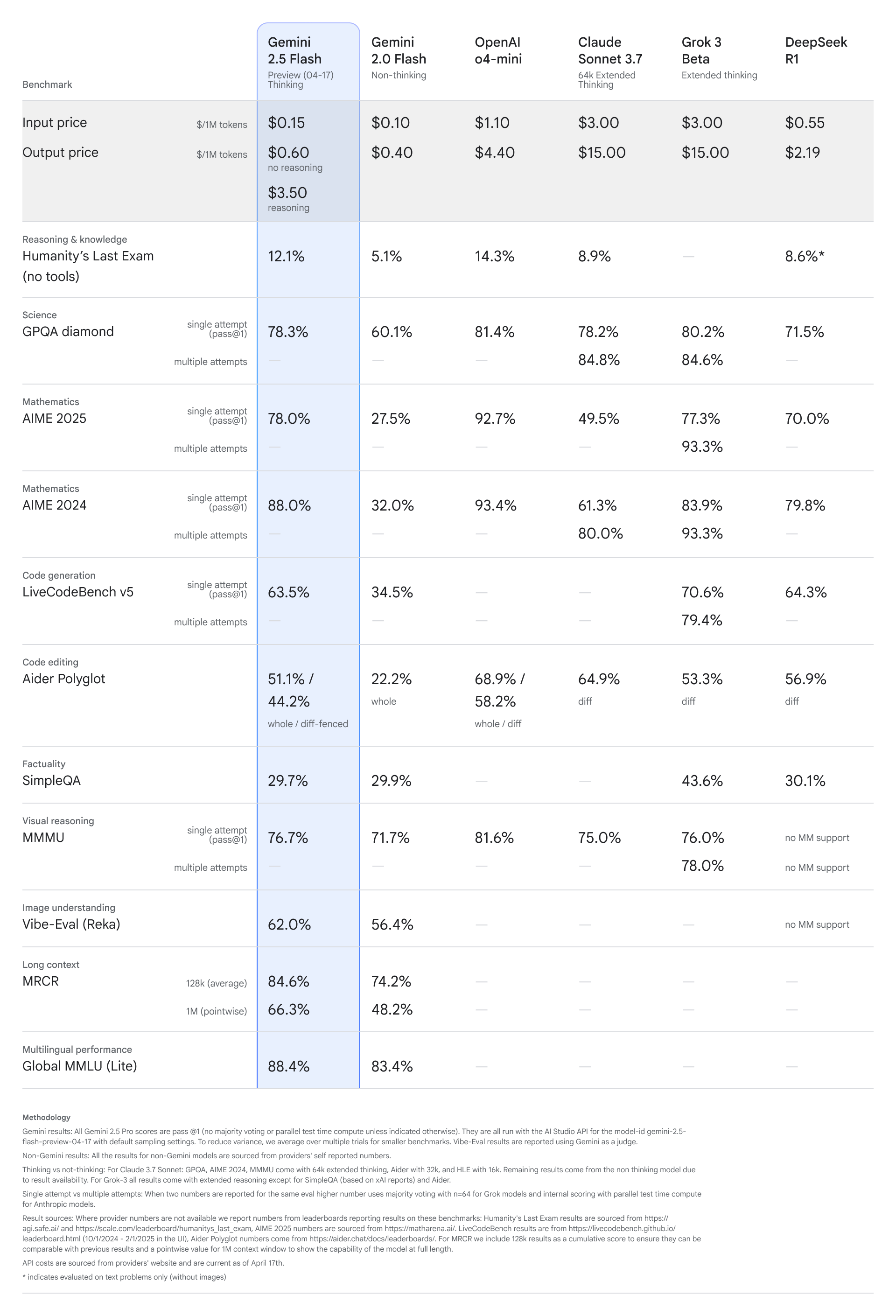
更重要的是,這種效能提升並未以犧牲效率或大幅增加成本為代價。Gemini 2.5 Flash 在多模態理解(MMMU, Vibe-Eval)、長上下文處理(MRCR 128k)以及多語言能力(Global MMLU Lite)方面也表現出色,分數均超越前代。其定價策略也體現了這種彈性:輸入成本為每百萬 Token $0.15,而輸出成本則根據是否啟用推理,分為 $0.60(無推理)和 $3.50(啟用推理)兩種模式。這使得開發者能夠根據具體任務需求,在獲得高品質推理結果與控制成本、追求低延遲之間找到最佳平衡點。

綜合來看,Gemini 2.5 Flash 在保持相對輕量與成本效益的同時,於多個關鍵能力維度上實現了顯著的效能躍升,特別是在需要複雜推理的數學、科學和程式碼任務上。其表現已逼近(甚至在某些特定指標超越)部分同級或更高階的模型,而可控的推理預算機制更賦予了其獨特的成本效益優勢。
Google 強調,這種可配置的推理預算機制,為開發者在成本、延遲與品質這三個關鍵因素之間,提供了更靈活的控制手段,使其廣泛適用於處理語言理解、資料分析、決策輔助等具有不同複雜度需求的任務。
開放預覽與未來展望
Gemini 2.5 Flash 目前已在 Google AI Studio、Gemini App 與 Vertex AI 平台開放預覽。開發者可以立即開始試用,並透過新的 thinking_budget 參數進行實驗。
Google 表示,將持續投入研發資源以改進 Flash 系列模型,並擴展其適用範圍。預計在模型進入正式發布(General Availability)階段之前,還會陸續釋出更多的版本更新與功能細節,值得開發者社群持續關注。




















