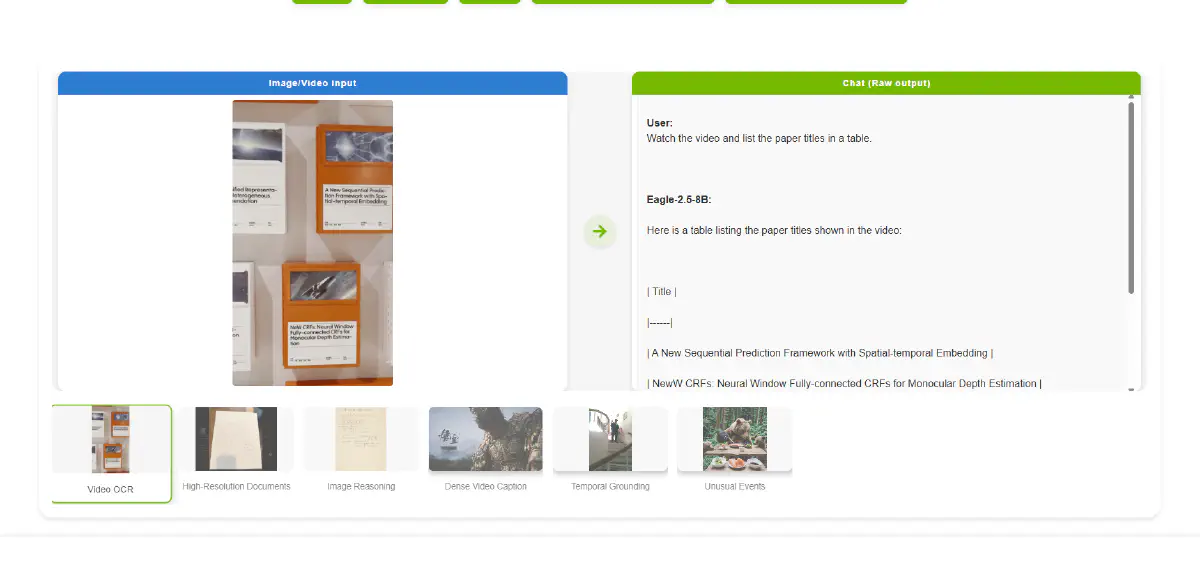
近期,由 輝達 (NVIDIA)、南京大學、香港理工大學 及 羅格斯大學 的研究團隊攜手合作,推出了一項名為 Eagle 2.5 的重大 AI 研究成果。這款專為 長上下文多模態學習 設計的視覺語言模型 (Vision Language Model, VLM),為業界在處理長影片理解和高解析度圖像方面所面臨的挑戰,提供了一個創新的解決方案。

核心亮點:8B 參數模型匹敵巨頭
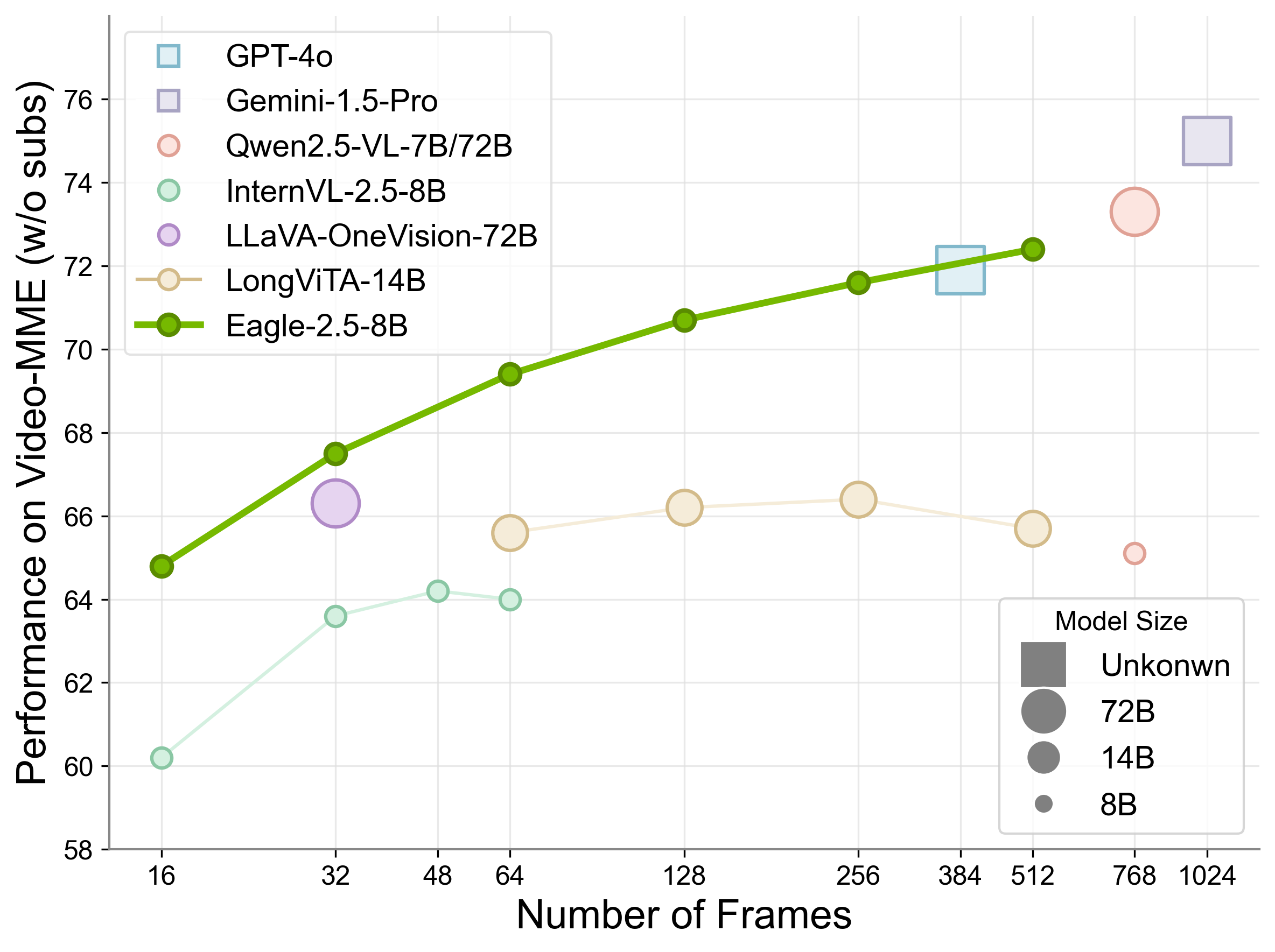
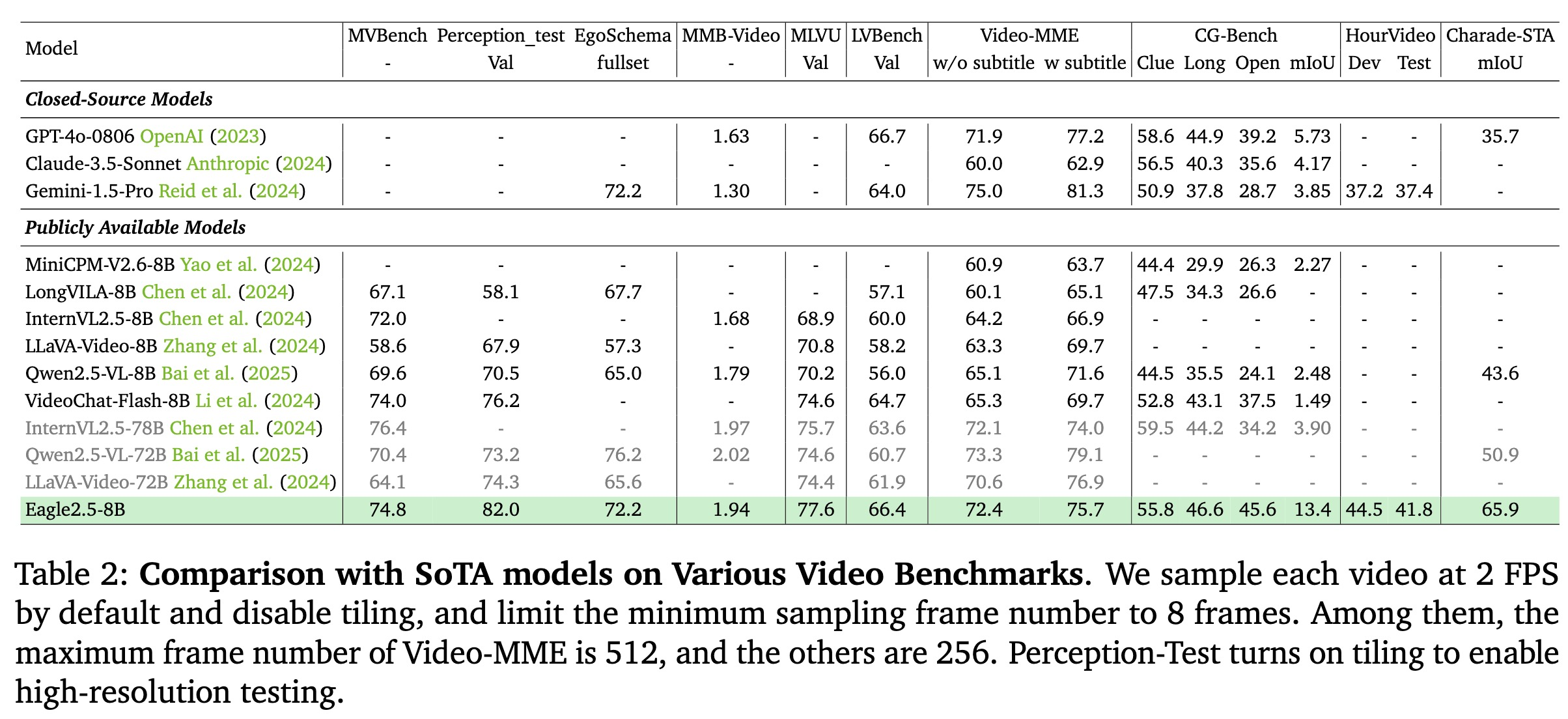
Eagle 2.5 最令人矚目的成就,在於其 驚人的效率與性能。其 80億參數版本 (Eagle 2.5-8B) 在多項基準測試中表現突出,尤其在 Video-MME 基準測試中(處理 512 個輸入幀),取得了 72.4% 的優異成績。
這項成果使其性能足以 媲美甚至超越 如 OpenAI 的 GPT-4o、阿里巴巴的 Qwen2.5-VL-72B 以及商湯科技的 InternVL2.5-78B 等參數規模遠大於自身的頂級商業及開源模型。這證明了透過架構和訓練方法的創新,可以在不無限擴大模型規模的前提下,達成頂尖的性能水平。
三大關鍵技術創新
Eagle 2.5 的卓越表現主要歸功於以下三大創新設計:
-
資訊優先採樣 (Information-First Sampling):
- 圖像區域保留 (Image Area Preservation, IAP): 優化圖像分割與處理方式,最大限度保留原始圖像的區域、長寬比及細節資訊,減少失真。
- 自動降級採樣 (Automatic Degradation Sampling, ADS): 根據上下文長度動態調整視覺與文字資訊的比例,確保文字完整性的同時,最大化利用視覺內容。
-
漸進式混合後訓練 (Progressive Mixed Post-Training): 在訓練階段逐步增加模型能處理的上下文長度 (如從 32K tokens 到 128K tokens),使模型能更好地適應不同長度的輸入,提升資訊密度,並穩定訓練過程。
-
多元化驅動的資料配方 (Diversity-Driven Data Recipe):
- 結合大量開源數據與團隊精心打造的 Eagle-Video-110K 資料集。
- 採用「先求多樣,再求質量」的數據收集策略,確保訓練資料的廣泛性與代表性,特別是補充了現有資料集中匱乏的長影片內容。
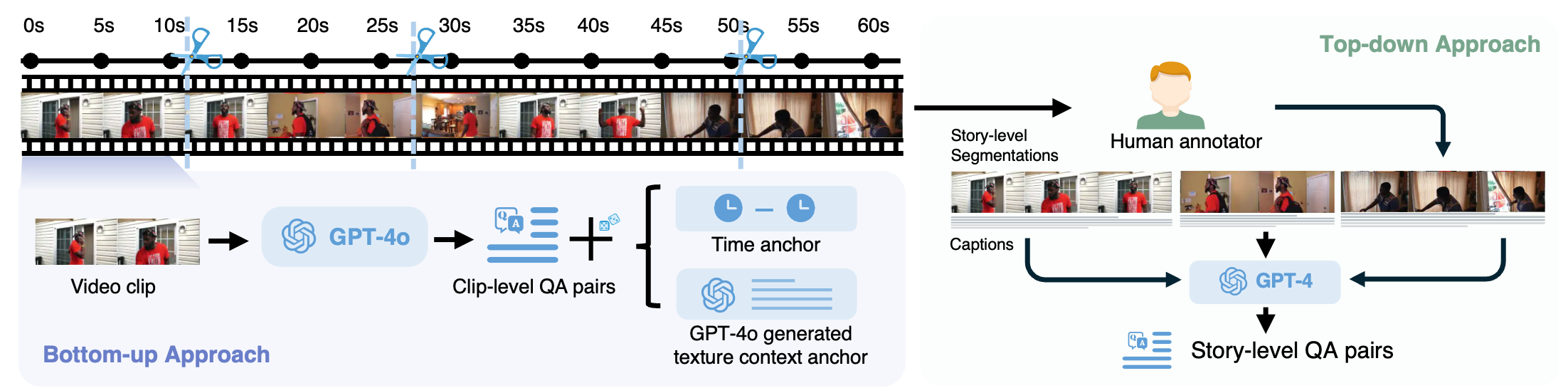
Eagle-Video-110K:專為長影片理解打造
為了解決現有資料集普遍缺乏長影片的問題,研究團隊特別創建了 Eagle-Video-110K 資料集。此資料集透過從多個來源收集影片,並利用 CLIP 嵌入進行多樣性篩選,顯著增加了訓練集中長影片的比例。其雙重標註流程(由上而下的章節描述/問答 + 由下而上的片段問答/時空錨點)為模型提供了更豐富、更深入的影片理解素材,顯著提升了模型處理高幀數 (≥128 幀) 影片的能力。
性能表現與獨特優勢
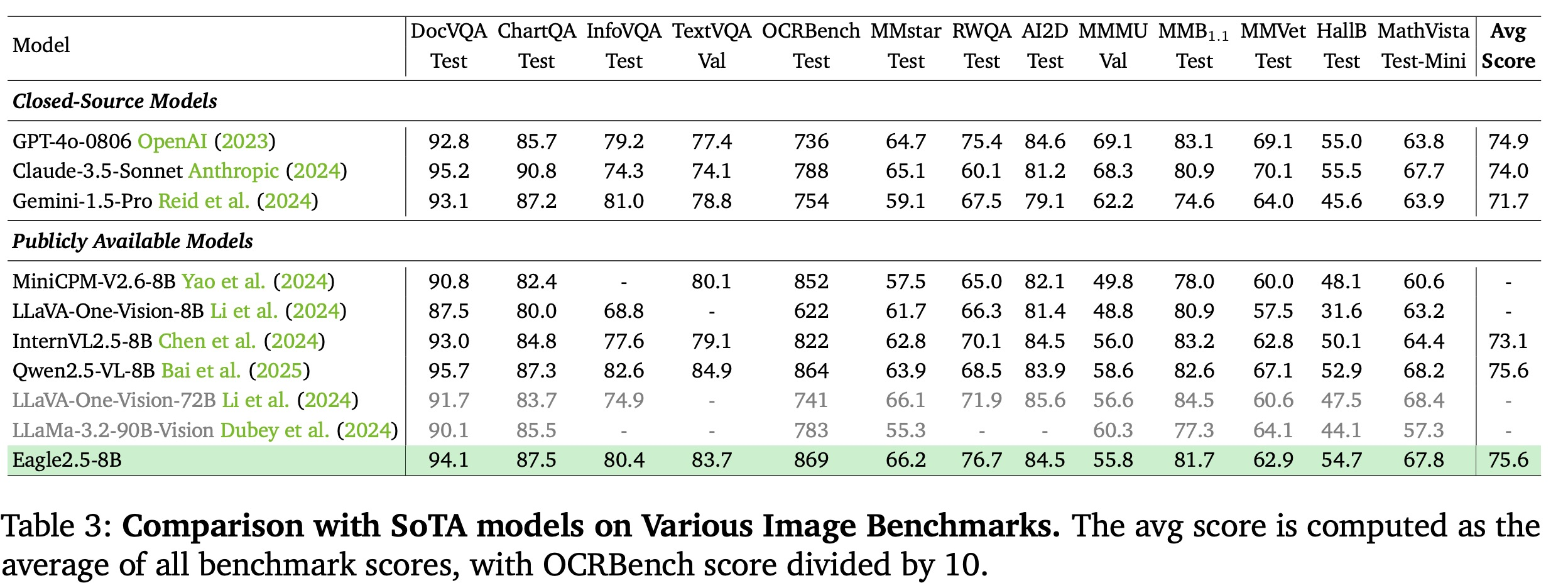
除了在 Video-MME 上的亮眼成績,Eagle 2.5-8B 在其他基準測試中同樣表現出色:
- MVBench: 74.8分
- MLVU (長影片理解): 77.6分
- LongVideoBench: 66.4 分
- DocVQA (文件問答): 94.1分
- ChartQA (圖表問答): 87.5分
- InfoVQA (資訊圖表問答): 80.4分
更重要的是,Eagle 2.5 展示了一個獨特的優勢:隨著輸入長度的增加,其性能能夠持續提升。這與許多僅僅優化了長序列處理能力,但性能並未隨之提升甚至下降的模型形成了鮮明對比。
Eagle 2.5 的成功,標誌著在無需龐大參數規模的條件下,實現高效能長上下文多模態理解的可能性。研究團隊認為,這項工作及其伴隨的 Eagle-Video-110K 資料集,將為未來開發更高效、更通用、更能應對複雜現實場景的視覺語言模型奠定基礎。
Eagle 2.5 的相關研究成果,包括 程式碼 以及 論文 已經開源,權重則還尚未釋出。但已經可以在 Hugging Face Space 上試用 Eagle 2.5-8B 的模型,體驗其在多模態理解任務上的表現。






















