
29日凌晨,阿里巴巴發布了全新的 Qwen3 系列大型語言模型,憑藉其在多項基準測試中的亮眼表現,足以與 DeepSeek R1、o3-mini 與 Gemini 2.5 Pro 等級的模型相提並論。更重要的是,Qwen3 全系列模型均採用 Apache 2.0 協議開源,允許自由使用與商用部署。
今天我們就來快速介紹 Qwen3 系列的更新重點,並告訴大家如何在本機或線上使用這些強大的模型。

Qwen3 模型亮點與架構更新
這次 Qwen3 系列的更新資訊相當豐富,其中最顯著的變化是引入了 混合專家 (Mixture-of-Experts, MoE) 架構,同時也保留了傳統的密集 (Dense) 模型版本。
MoE 模型
本次推出了兩款 MoE 模型:
- Qwen3-235B-A22B: 旗艦級模型,總參數量 235B,推論時啟用 22B 參數。
- Qwen3-30B-A3B: 較小型的 MoE 模型,總參數量 30B,推論時僅啟用 3B 參數。
Qwen 團隊特別提到,Qwen3-30B-A3B 僅需自家先前 QwQ-32B 推理模型約 10% 的啟用參數,就能達到更佳的效果,展現了 MoE 架構在高效率方面的潛力。
密集模型
密集模型的參數規模與前代類似,但有所調整:
- 提供 0.6B、1.7B、4B、8B、14B、32B 等多種尺寸。
- 值得注意的是,本次未推出 72B 的密集模型版本。
驚人的基準測試表現
Qwen3 在多個權威基準測試中都取得了優異的成績。
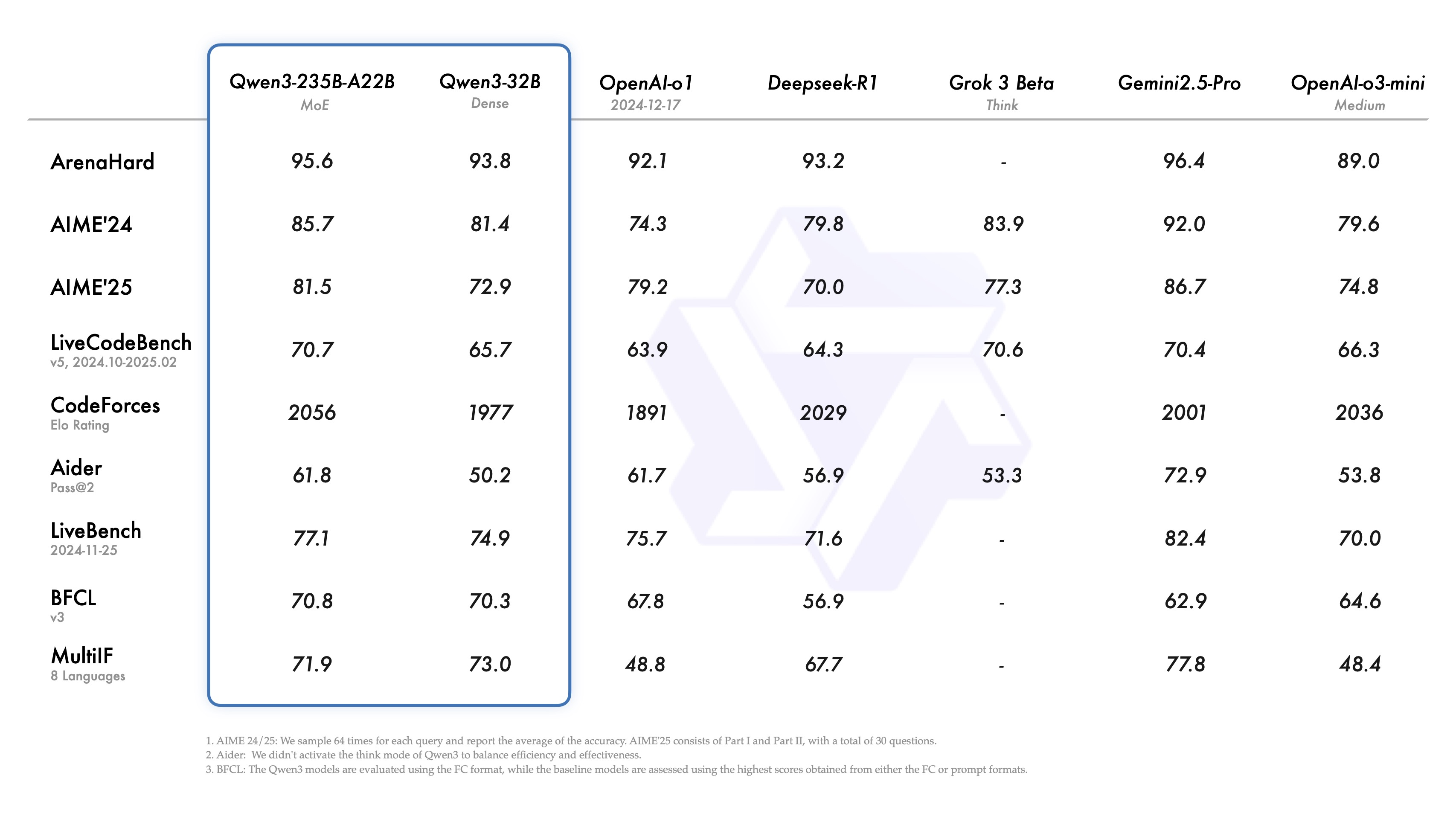
旗艦模型 (Qwen3-235B-A22B)
- 綜合能力 (Arena Hard): 獲得 95.6% 的分數,小輸 Gemini 2.5 Pro (96.4%),但已超越 OpenAI o3-mini 和 DeepSeek R1。
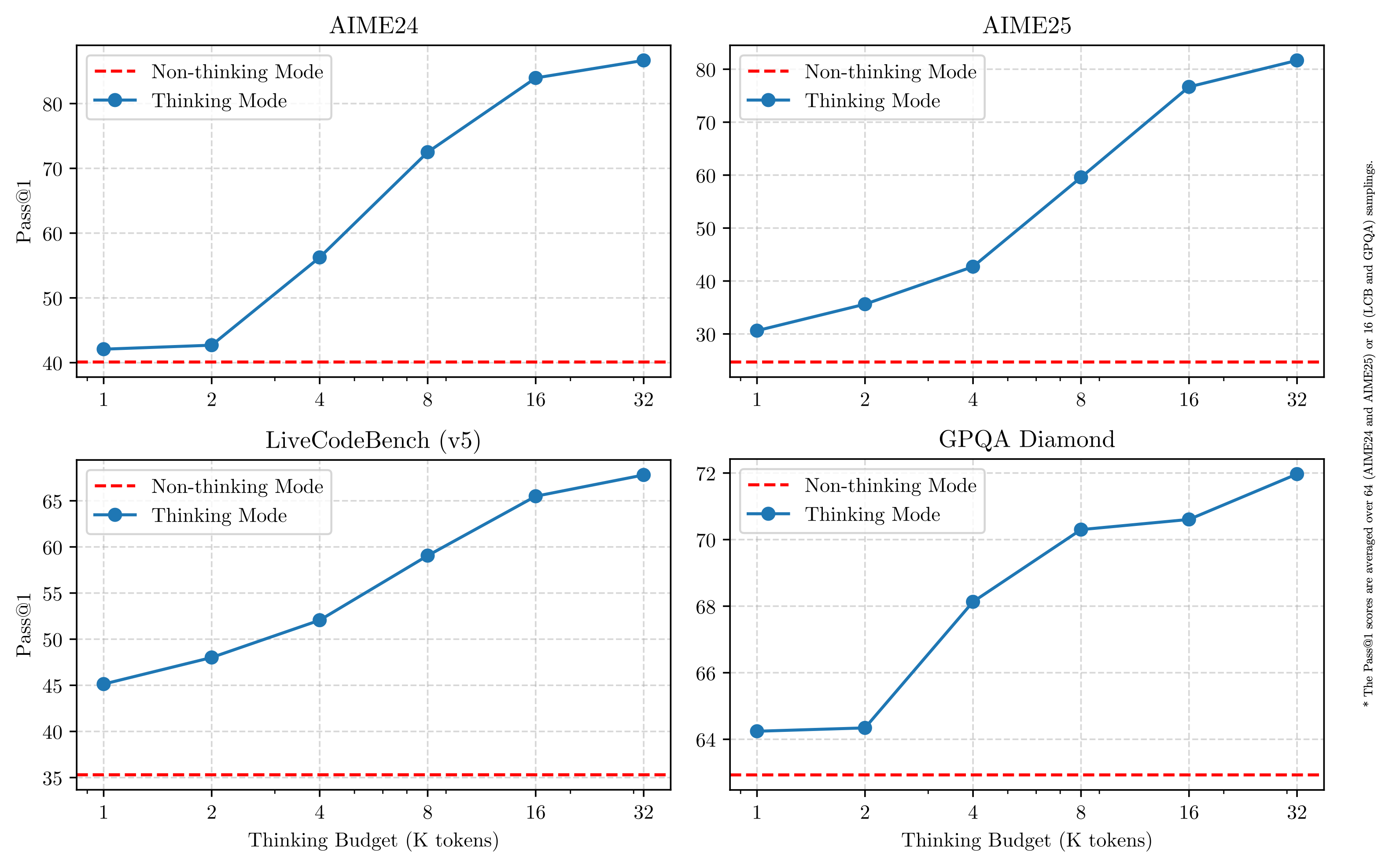
- 數學能力 (AIME 2024 & 2025): 分別獲得 85.7% 和 81.5% 的高分,雖不及 Gemini 2.5 Pro (92%, 86.7%),但在 AIME 2024 上已超越 o3-mini 和 Grok-3 Beta。
- 程式能力 (LiveCodeBench V5): 取得 70.7% 的分數,與 Gemini 2.5 Pro (70.4%) 和 Grok-3 Beta (70.6%) 處於同一水平,超越了 o3-mini、o1 和 DeepSeek R1。
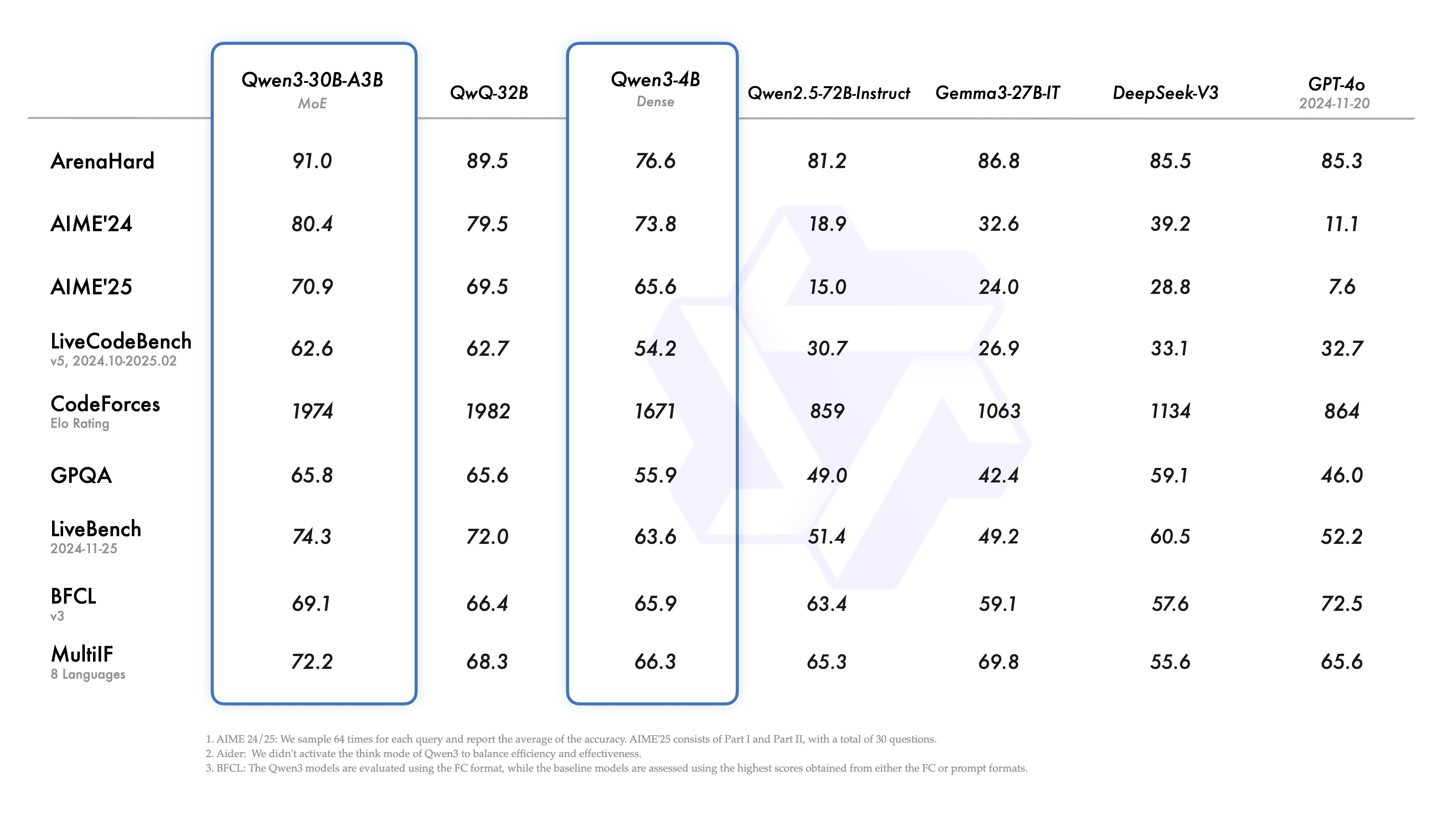
中型 MoE 模型 (Qwen3-30B-A3B)
這款模型因其較低的運行需求而備受關注,特別適合在消費級硬體上運行。
- 與 Gemma 3 27B 比較: 在多項測試中全面勝出。
- 與 DeepSeek R1 比較: 展現出壓倒性優勢。
- 與自家 Qwen-Agent-32B 比較: 成績小幅超越,但啟用參數僅為 3B。
這優異的表現部分歸功於 Qwen3 全系列支援 Chain-of-Thought (CoT),以及龐大的訓練數據和先進的訓練技術。
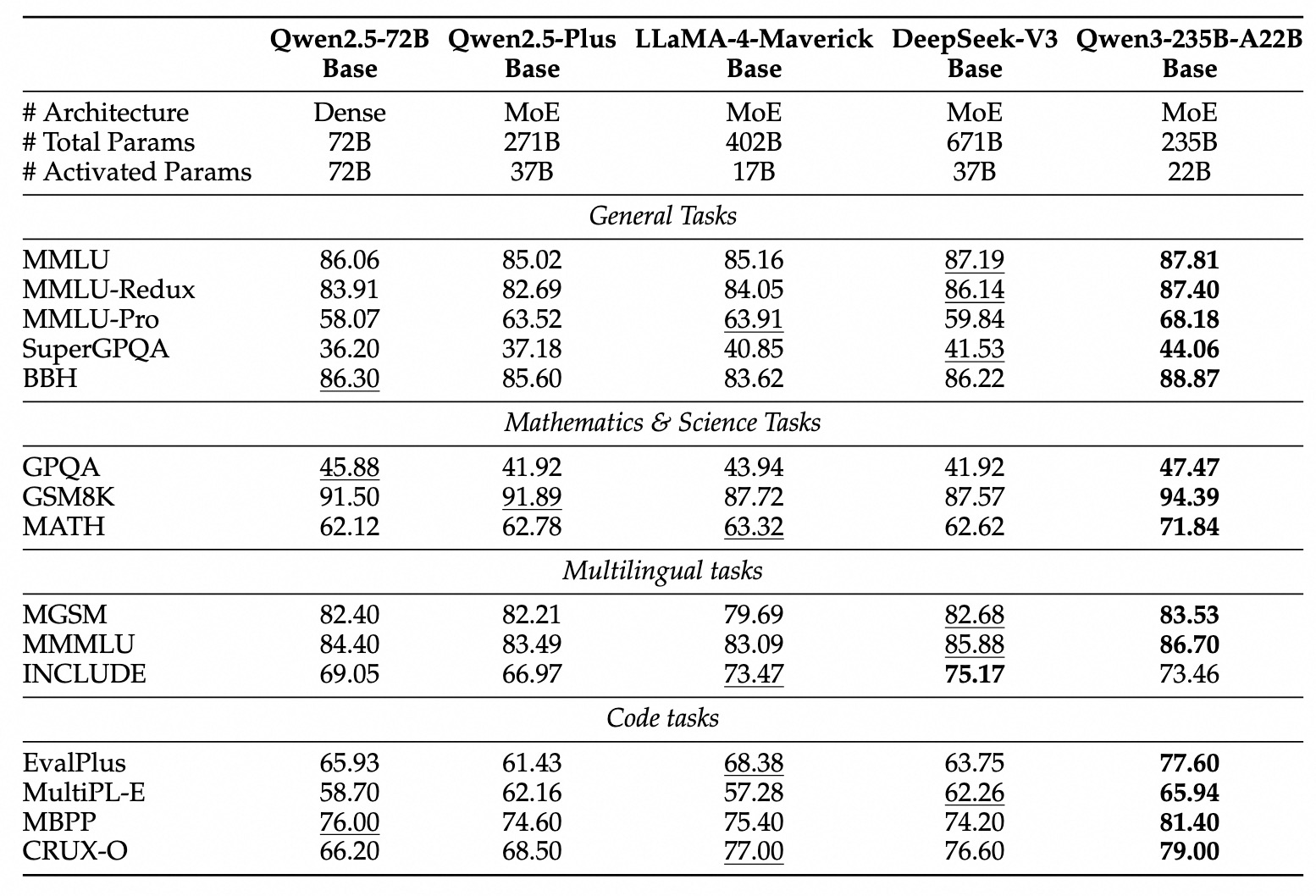
訓練數據與特色功能
龐大且多樣的訓練數據
- 預訓練: 使用了近 36 兆 Tokens 的數據,幾乎是 Qwen2.5 系列的兩倍,涵蓋 119 種語言與方言,提升了多語言能力。
- 後訓練: 包含長思維鏈指令微調、長思維鏈強化學習、思維模式融合、通用強化學習等多階段優化。
- 蒸餾: 使用 Qwen3-235B-A22B 蒸餾出 Qwen3-30B-A3B,使用 Qwen3-32B 蒸餾出其餘小型密集模型。
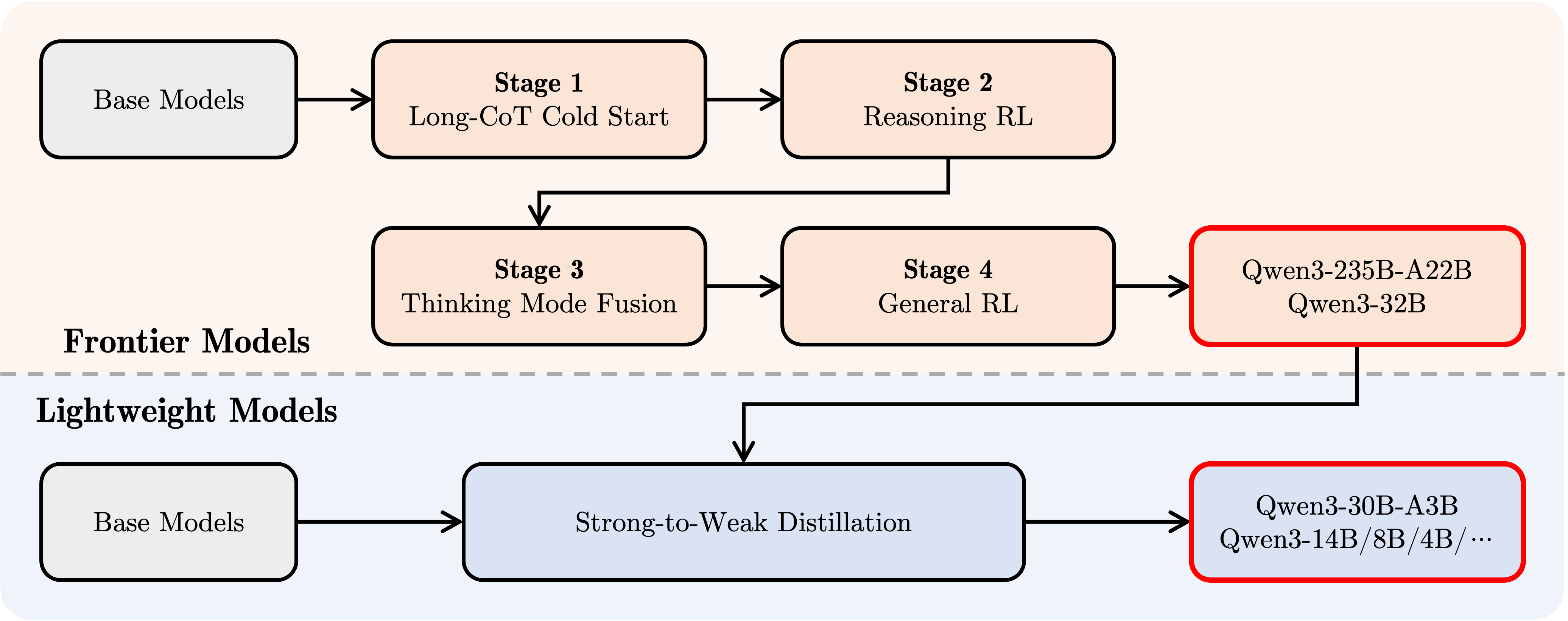
特色功能
- Chain-of-Thought (CoT): 全系列支援 CoT,提升複雜推理能力。
- 推理預算 (Inference Budget): 類似 Google Gemini 2.5 Flash 的功能,允許用戶設定模型思考時使用的 Token 上限。這對於工具調用等僅需指令遵循能力的簡單任務,可以顯著減少思考時間和資源消耗。也有助於控制整體服務成本。
Qwen3-4B 的驚人宣稱
根據官方資料,Qwen3-4B 的表現甚至能與上一代旗艦 Qwen2.5-72B 相當甚至超越。不過,考量到參數量的巨大差異,對此說法個人持保留態度。
如何使用 Qwen3 模型
目前有多種方式可以體驗 Qwen3:
-
Qwen 官方聊天介面: 官方網站已提供 Qwen3-235B-A22B, Qwen3-30B-A3B 和 Qwen3-32B 的線上試用。
-
Ollama 本地部署: 如果你的電腦安裝了 Ollama,可以直接在終端機運行以下指令下載並運行模型:
1 2 3 4 5# 運行模型 (若未下載會自動下載) ollama run qwen3:30b # 或其他模型標籤,如 32b, 14b, 4b 等 # 僅下載模型 ollama pull qwen3:30b注意: 在 Ollama 上,
qwen3:30b和qwen3:30b-a3b指向的是同一個 MoE 模型 (Qwen3-30B-A3B),可以從模型檔案的雜湊值確認。
Qwen3 模型能力實測
接下來,我們透過一些實際任務來測試 Qwen3 的表現。測試主要在 Qwen 官方線上介面進行,部分測試使用本地 Ollama 運行的 Q4 量化版 Qwen3-30B-A3B。
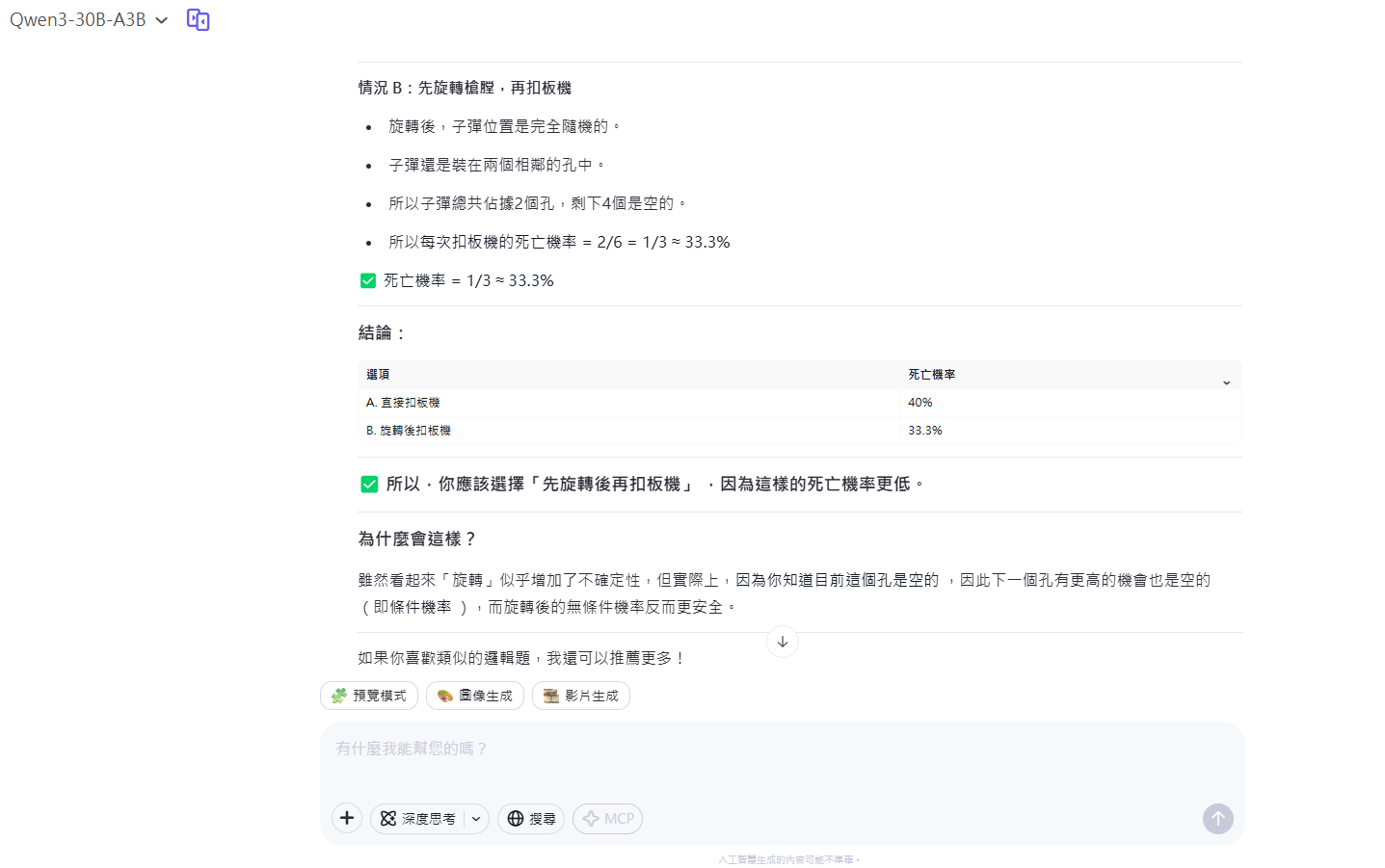
1. 邏輯推理 (左輪手槍問題)
現在請回答這個邏輯思考題:
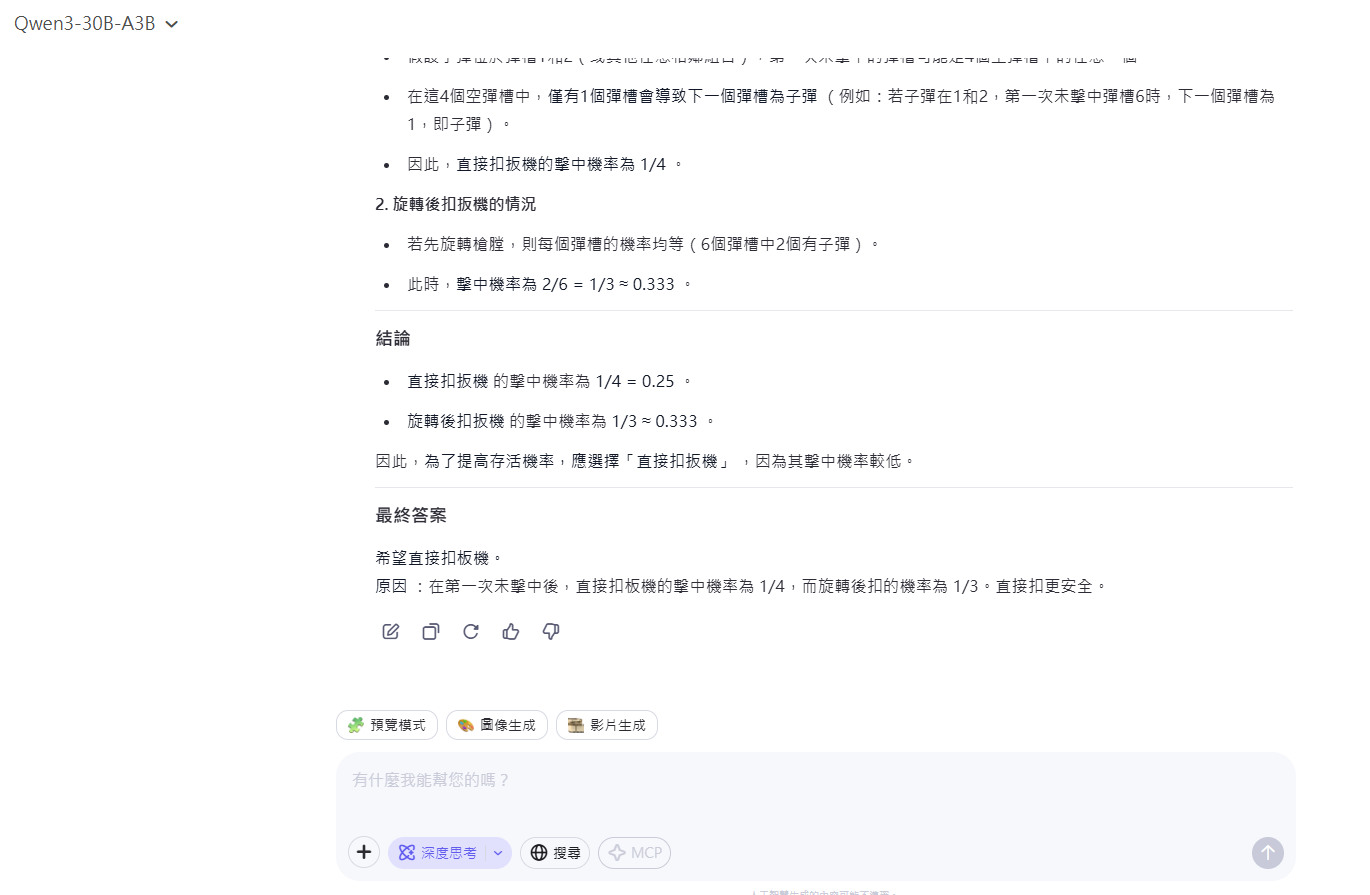
想像你正被綁在椅子上動彈不得,歹徒拿著一把6個槍膛全空的左輪手槍,再裝兩顆子彈進兩個緊鄰的槍膛內,並旋轉槍膛。然後對著你的腦袋扣板機一下,很幸運你還活著,這時他說再扣一次板機就放你走,你希望先旋轉後再扣或直接扣板機?為什麼?
- 開啟推理模式 (CoT): 線上版的三個模型 (235B-A22B, 30B-A3B, 32B) 都能正確解答經典的左輪手槍概率問題。
- 關閉推理模式: Qwen3-30B-A3B 無法答對,但 235B 和 32B 依然能正確計算。
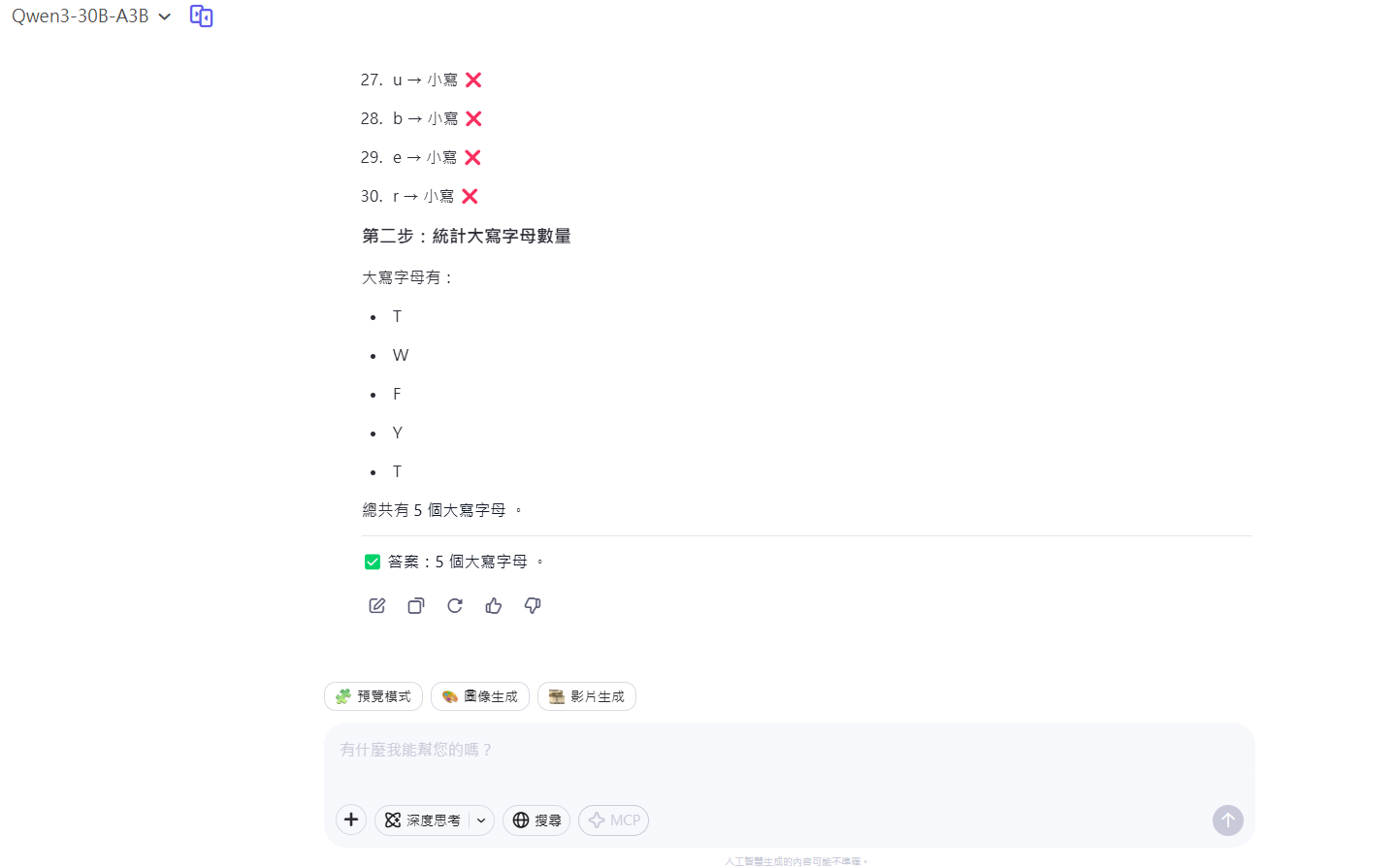
2. 計數任務 (大寫字母數量)
- 問題: 計算 “The Walking Fish is a YouTuber” 中的大寫字母數量 (答案應為 5: T, W, F, Y, T)。
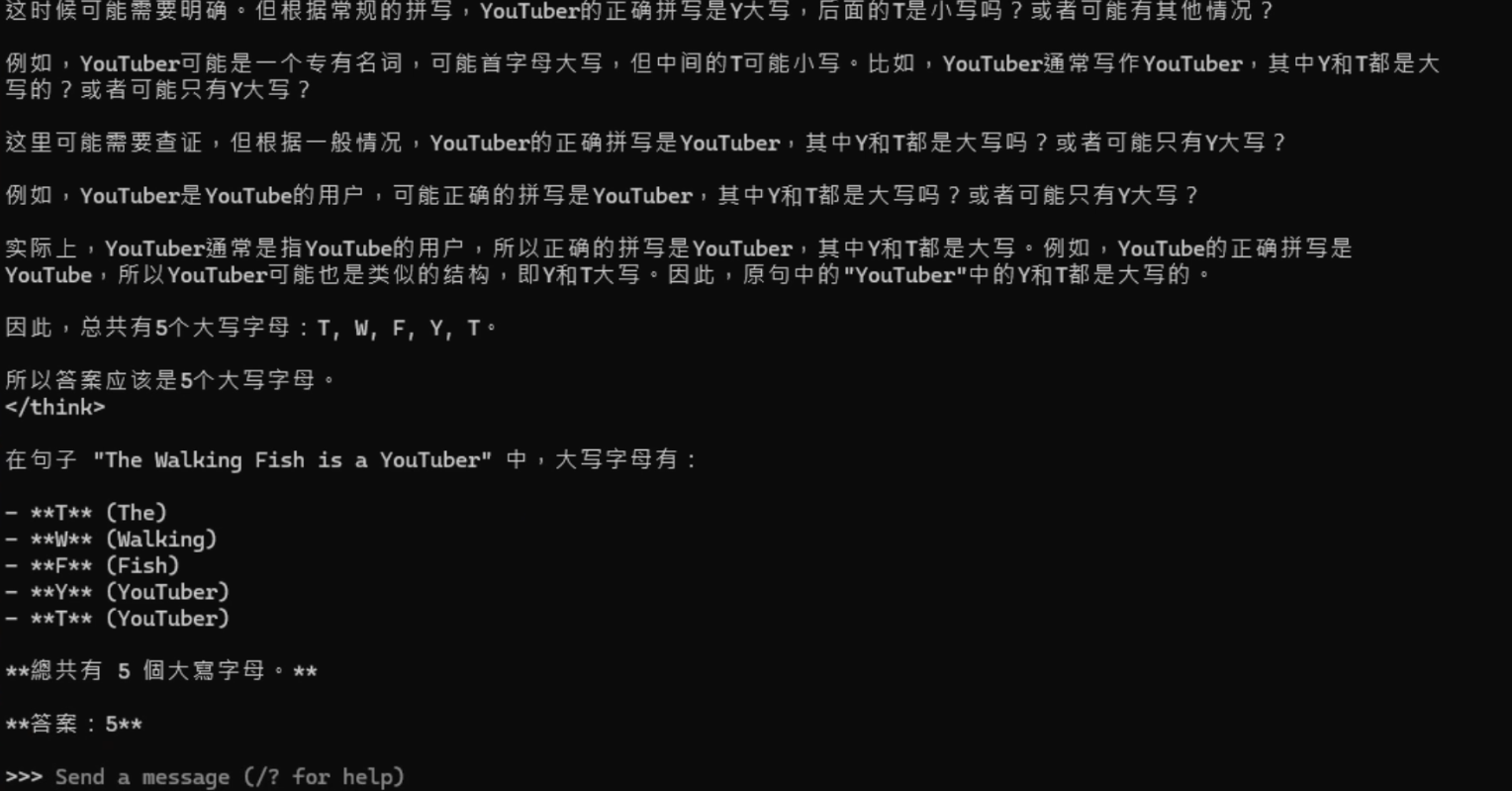
- 結果: 線上版三個模型,無論是否開啟推理,都能正確回答 5 個。本地 Q4 量化的 30B-A3B 也能正確回答,但思考過程中不知道為什麼一直對 “YouTuber” 的 Y 和 T 是否都應大寫而糾結。
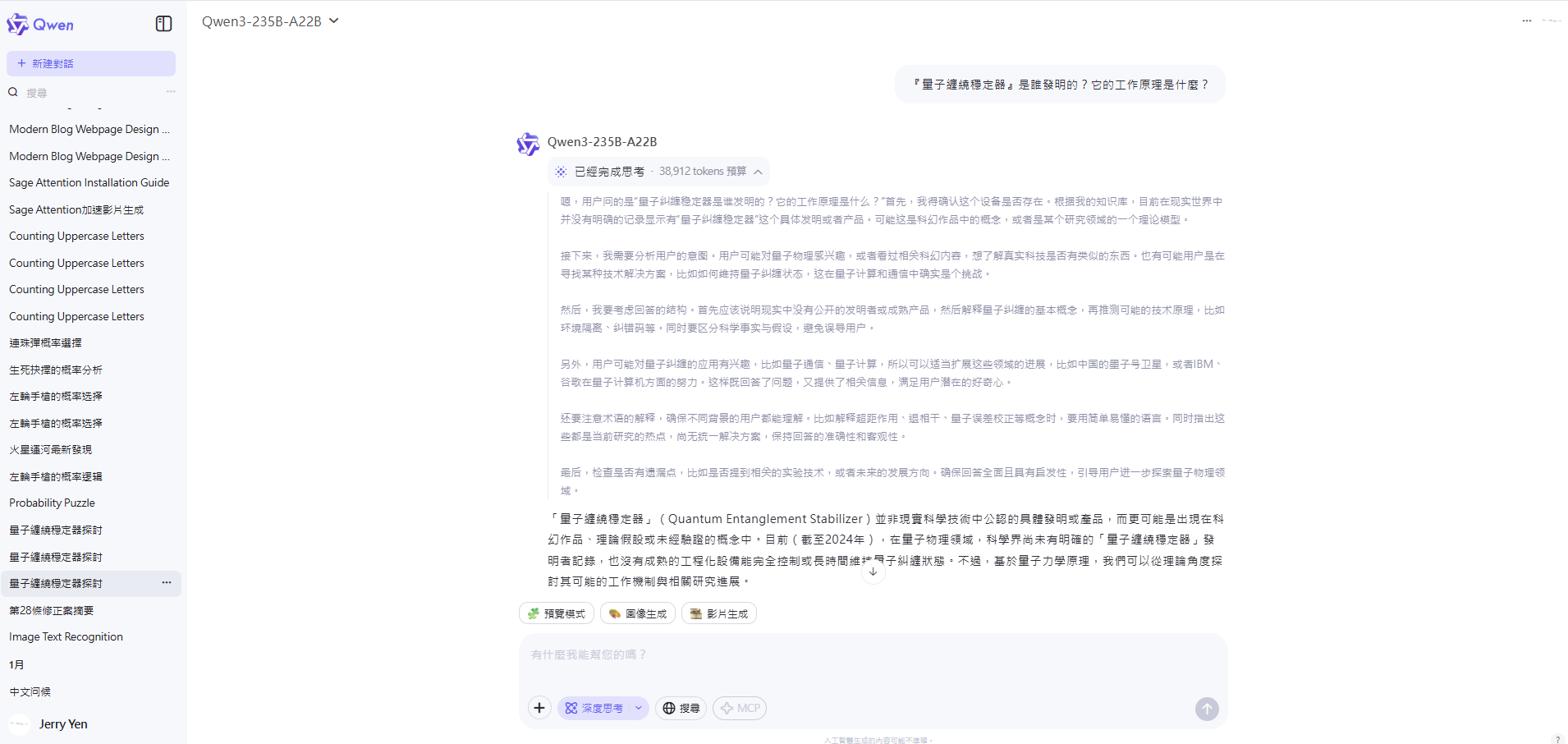
3. 幻覺測試 (辨識虛構概念)
- 問題 1: 解釋什麼是 “量子纏繞穩定器” (Quantum Entanglement Stabilizer)?
- 結果: 無論是否開啟思考,Qwen3 都能正確辨識出這是一個不存在的虛構裝置,表現良好。
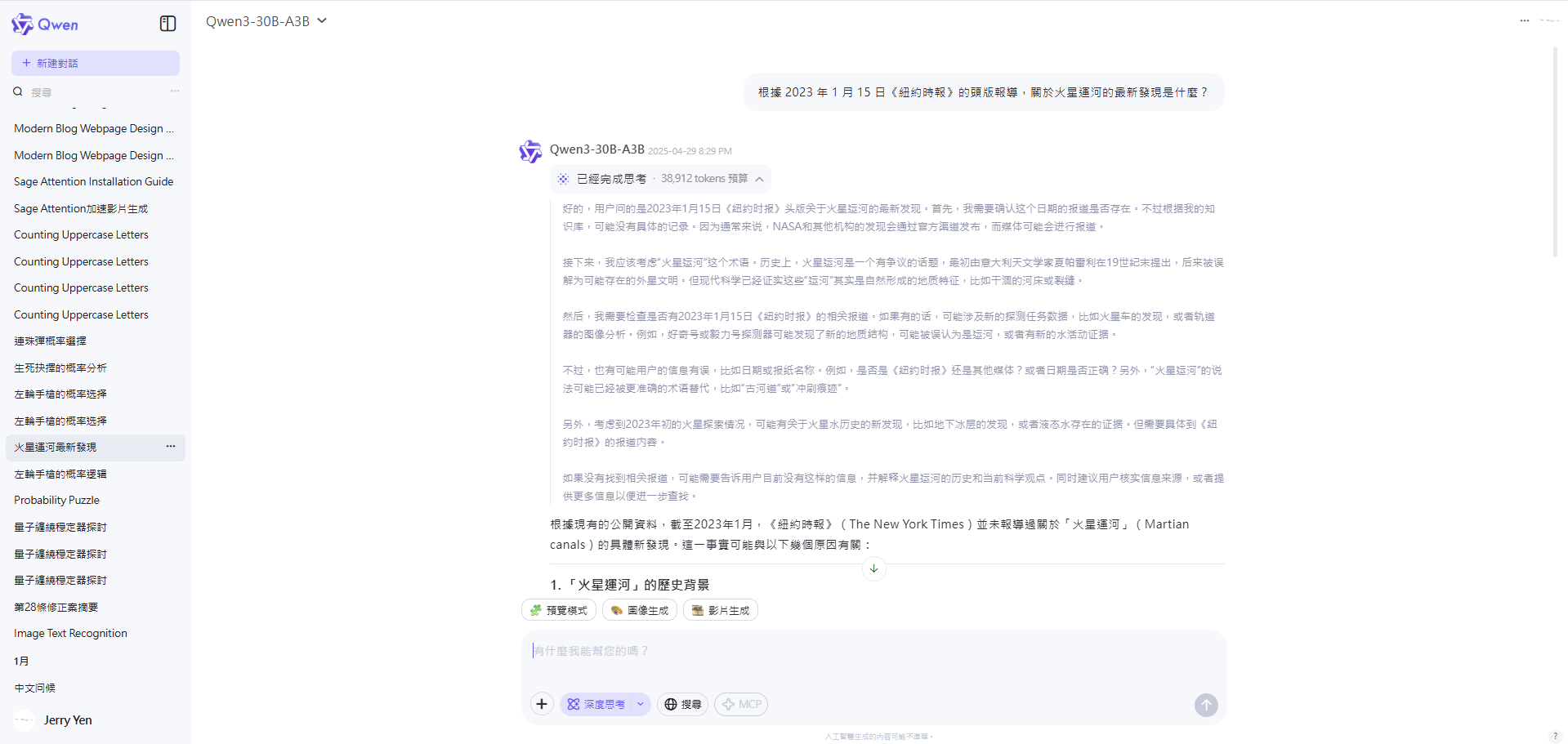
- 問題 2: 詢問 2023 年 1 月 15 日紐約時報關於 “火星運河最新發現” 的頭條?
- 結果: 模型沒有胡亂編造新聞,反而解釋了 “火星運河” 一詞的歷史由來,表現不錯。
4. 長文本處理與內容生成 (影片逐字稿轉文章)
將上一部影片的逐字稿輸入給 Qwen3-235B-A22B (開啟深度思考),要求其根據提供的 Hugo Markdown 模板生成文章。
-
指令遵循: 未能完全遵循 “收到訊息僅回覆 OK” 的初步指令,而是做了一個簡單總結 (可能與深度思考模式有關)。
-
文章生成質量: 生成的文章整體通順,邏輯清晰,並適當使用表格呈現資訊,效果不錯,甚至某些部分優於原始發布版本。
-
發現幻覺問題: 在看似表現良好的情況下,仔細檢查發現了多處幻覺:
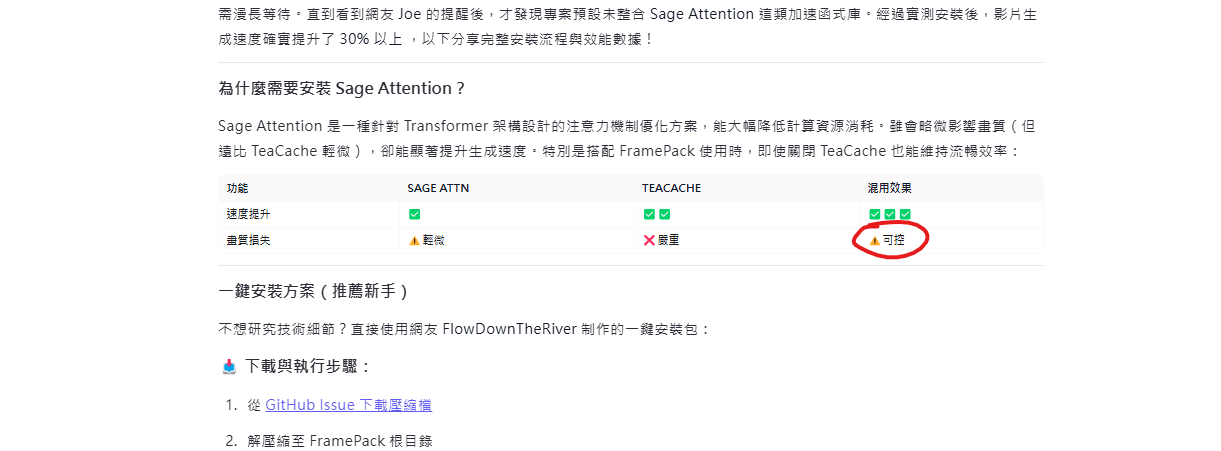
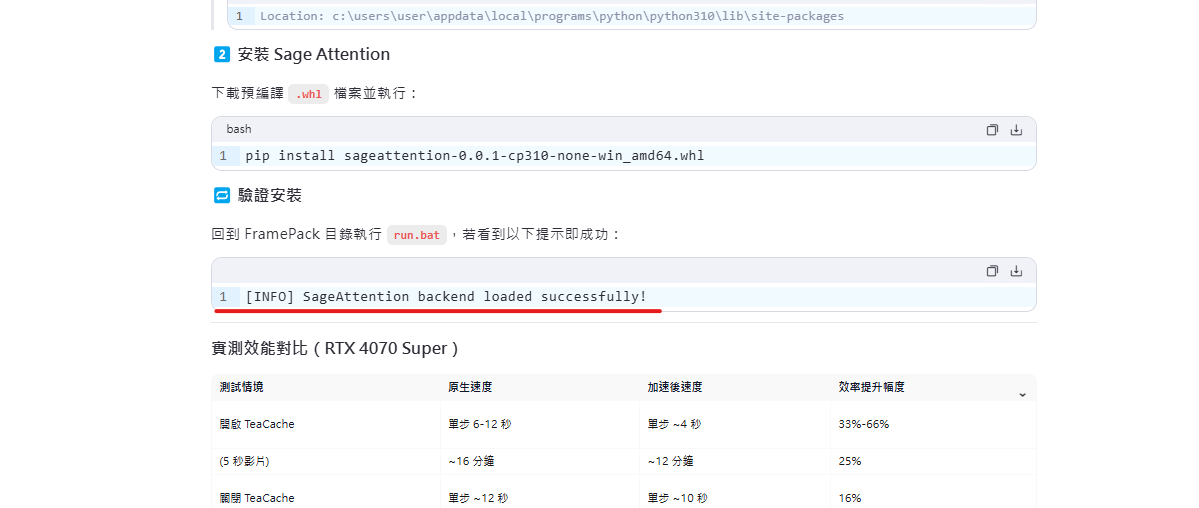
- Sage Attention 安裝: 提供了逐字稿中未提及,甚至與影片操作 (直接用網路來源) 不符的安裝檔案名稱。
- 驗證安裝: 提示訊息為自行編造。
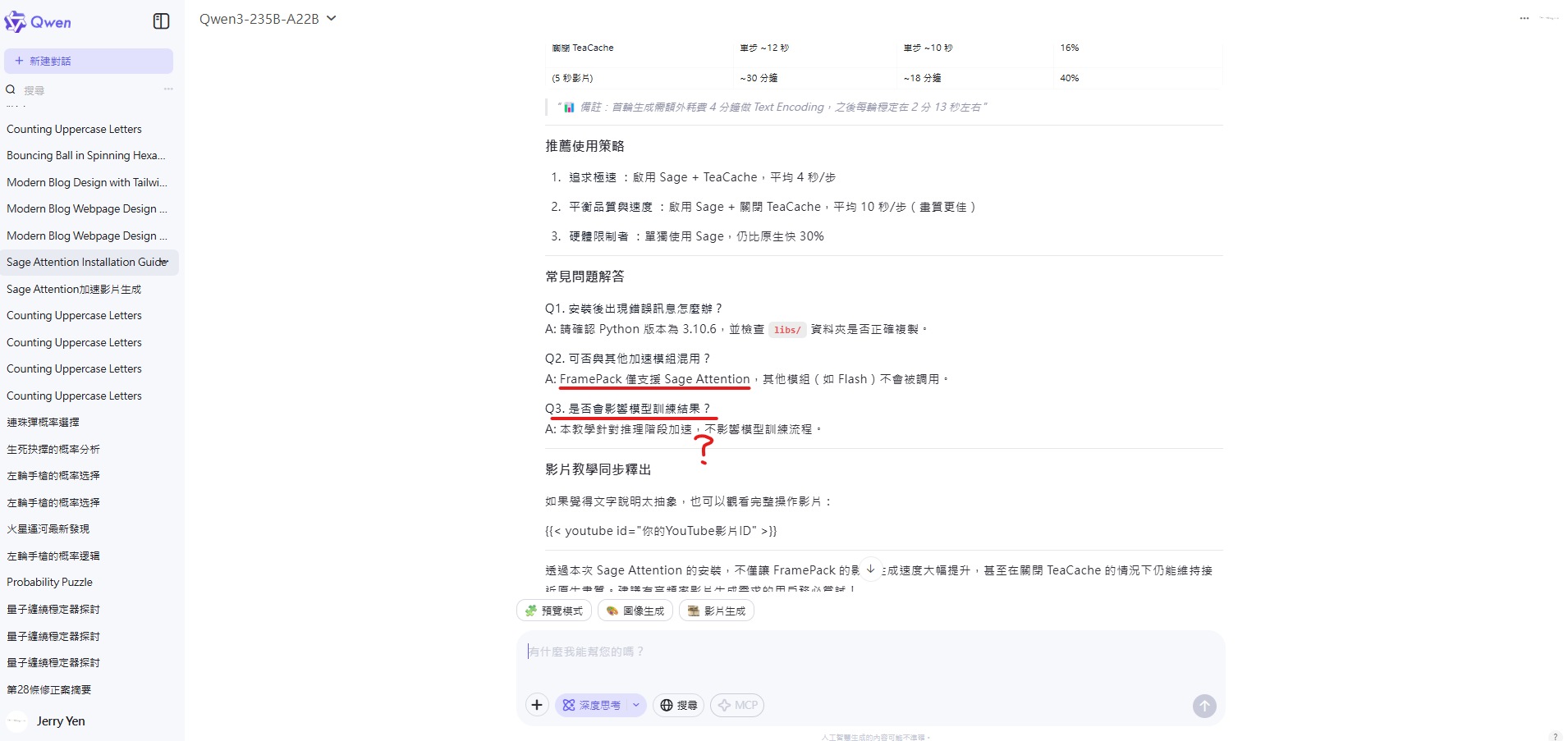
- 常見問題解答:
- 關於 Sage Attention 與其他加速模組混用問題的回答完全錯誤 (影片明確提到 FramePack 會優先調用 Sage Attention 而非只能調用 Sage Attention)。
- 關於是否影響模型訓練結果的問題完全是無中生有。
- 關於 Sage Attention + TeaCache 畫質損失的描述不準確 (應與僅開 TeaCache 類似或更嚴重)。
結論: 即使提供了上下文資訊,Qwen3 在處理長文本並生成結構化內容時,仍可能產生明顯的幻覺,需要仔細核對輸出。
5. 程式能力
- 網站生成: 使用之前測試 Gemini 2.5 Pro 的提示詞,要求 Qwen3-235B-A22B 生成一個個人網站。
- 結果 (235B): 生成效果不錯,設計感尚可,與現有網站各有千秋。部分細節 (如電子報訂閱區塊樣式) 可再優化。
- 結果 (30B / 32B): 相較之下表現普通。
- (註: 為何不測 LeetCode?) 目前頂級 LLM 在處理 LeetCode 這類單一演算法問題上已非常強大,甚至超越多數人類。更複雜的專案規劃、代碼整合與設計美感才是區分模型能力的關鍵。
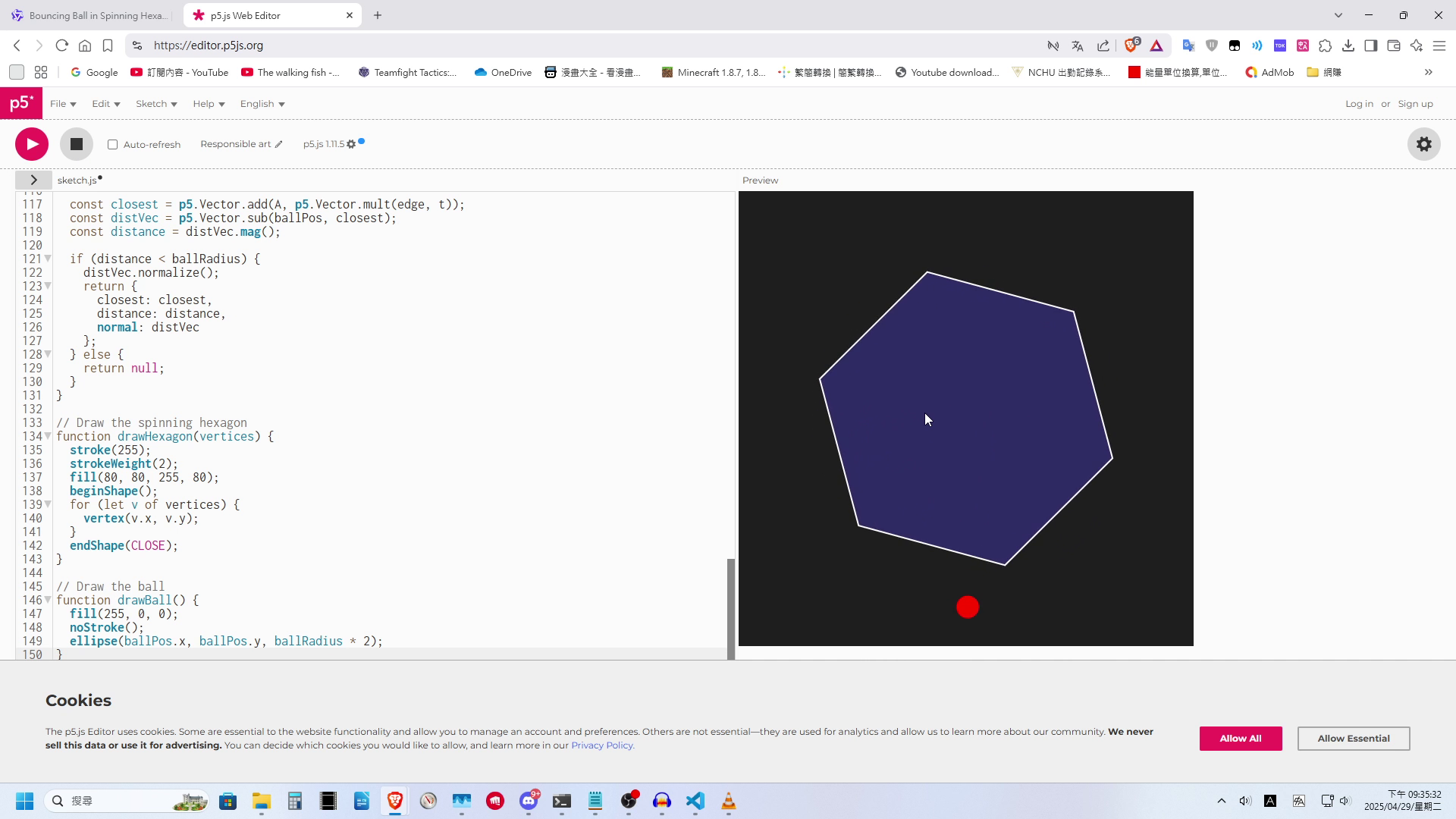
- 物理模擬 (六邊形內彈跳小球): 要求使用 P5.js 生成一個小球在六邊形內按物理規律反彈的動畫。
- 結果 (235B): 表現令人失望。經過長達 5 分鐘的思考,生成的程式碼中,小球直接穿過了六邊形,沒有任何碰撞檢測與反彈效果。此結果與先前測試 DeepSeek R1 時類似。
總結與展望
總體而言,Qwen3 系列模型的發布無疑是開源社群的一大福音。
優點:
- 性能強勁: 尤其是旗艦模型 Qwen3-235B-A22B,在多項基準測試中達到頂尖水平,超越了現有的許多開源模型,甚至逼近頂尖的閉源模型。
- 高效 MoE: Qwen3-30B-A3B 以極低的啟用參數展現了不俗的性能,非常適合資源有限的本地部署。
- 完全開源: Apache 2.0 協議對個人和企業用戶都非常友好。
- 特色功能: 內建 CoT 和推理預算控制,增加了模型的靈活性和可用性。
缺點:
- 仍有幻覺: 即使在提供上下文的情況下,進行複雜內容生成時仍可能出現明顯的幻覺和事實性錯誤。
- 複雜程式能力待加強: 在需要較強空間邏輯和物理理解的程式任務 (如物理模擬) 中表現不佳。
- 與頂尖閉源模型差距: 雖然表現優異,但相較於 Gemini 2.5 Pro 或 Claude 3.7 Sonnet 等頂尖閉源模型,在某些方面可能仍有差距。
Qwen3-235B-A22B 雖然參數總量 (235B) 仍相當可觀,但其 MoE 架構使得實際運行時僅需激活 22B 參數,效率遠超同等性能的模型。以 Deepseek R1 約 1/3 的總參數量、更低的啟用參數量,在多方面實現超越,確立了其在開源領域的領先地位。
對於普通用戶而言,Qwen3-30B-A3B 無疑是一款值得嘗試的高性價比模型。後續可能會測試將其與 Cline 等開發工具整合使用的效果。
由於本次評測時間較為倉促,未能進行更全面的測試。但初步看來,Qwen3 系列,特別是其 MoE 模型,為開源 AI 的發展注入了新的活力。
然後確定可以將前一段時間發布,堪稱笑話的 Llama 4 給忘掉了。




















