
Bert-VITS2 這個專案是目前複製聲音技術中,算是比較好上手效果又特別好的。我自己也簡單的寫了個 Colab 記事本,讓大家可以更方便的使用這個專案。
而今天也主要會跟大家介紹如何在 Colab 上訓練 Birt-VITS2。
當然,既然是在講聲音複製技術,在一開頭就來給大家聽聽看,Bert-VITS2所複製出來的聲音。
以上的結果僅有使用 8 分鐘左右的錄音,並且只訓練 2000 個 Step,但效果卻非常的好,可見該專案的強大。
那麼接下來就開始跟大家介紹,該如何使用這個專案。
Bert-VITS2 GitHub頁面:
https://github.com/fishaudio/Bert-VITS2
聲明
在開始之前這邊要先發個聲明,近期 YouTube 對聲音複製相關的影片管理的會變比較嚴,主要是因為擔心這方面的技術會被拿來散佈假消息。所以這邊還是要發個聲明,今天這部影片只是做一個簡單的教學,並不是要拿來複製誰的聲音,沒有什麼惡意的用途,只是帶大家認識一下新的技術,以及提醒大家要稍微多多的提防。
現在只要稍微有一點點技術能力就可以做到非常逼真的聲音複製效果。
訓練資料處理
首先在開始訓練前,這邊建議可以先處理好訓練資料,避免浪費寶貴的 Colab 使用時間。
訓練資料處理的部分,這邊提供兩種方法。
-
一種是乖乖自己在本機上處理完成,然後在執行 Colab 時上傳。優點是調整文字標記比較方便,缺點是比較麻煩。
-
第二種則是直接開 Colab 記事本,上傳音檔後使用我寫在記事本中的處理區塊。優點是只要上傳音檔就可以了,缺點是 Whisper 的辨識有可能出錯。Bert-VIT2前後文對生成結果的影響比較大。
以下兩種都會介紹,大家可以自行選擇
本機上處理訓練資料
Bert-VITS2 的訓練資料有指定的格式,格式如下 (以下複製自Bert-VITS2儲存庫):
|
|
其中,raw 文件夹下保存所有的音频文件,esd.list 文件为标签文本,格式为
|
|
例如:
|
|
我們需要將每一個音檔,放在 raw 資料夾中,並在 esd.list 中為其標註{檔名}、{說話者}、{語言}、{說話內容}

這邊提供給大家一個方法,大家可以使用 Whisper 做語音辨識,將輸出的 .srt 檔修改好。再簡單些個 Python 腳本,依照 .srt 檔來切割音檔,並儲存每一句字幕作為標註。
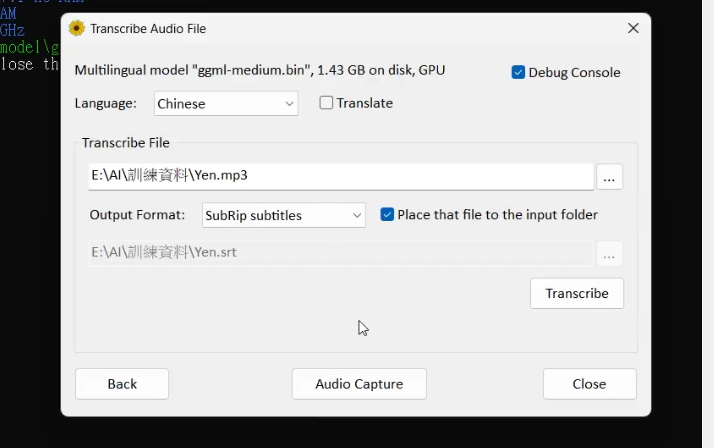
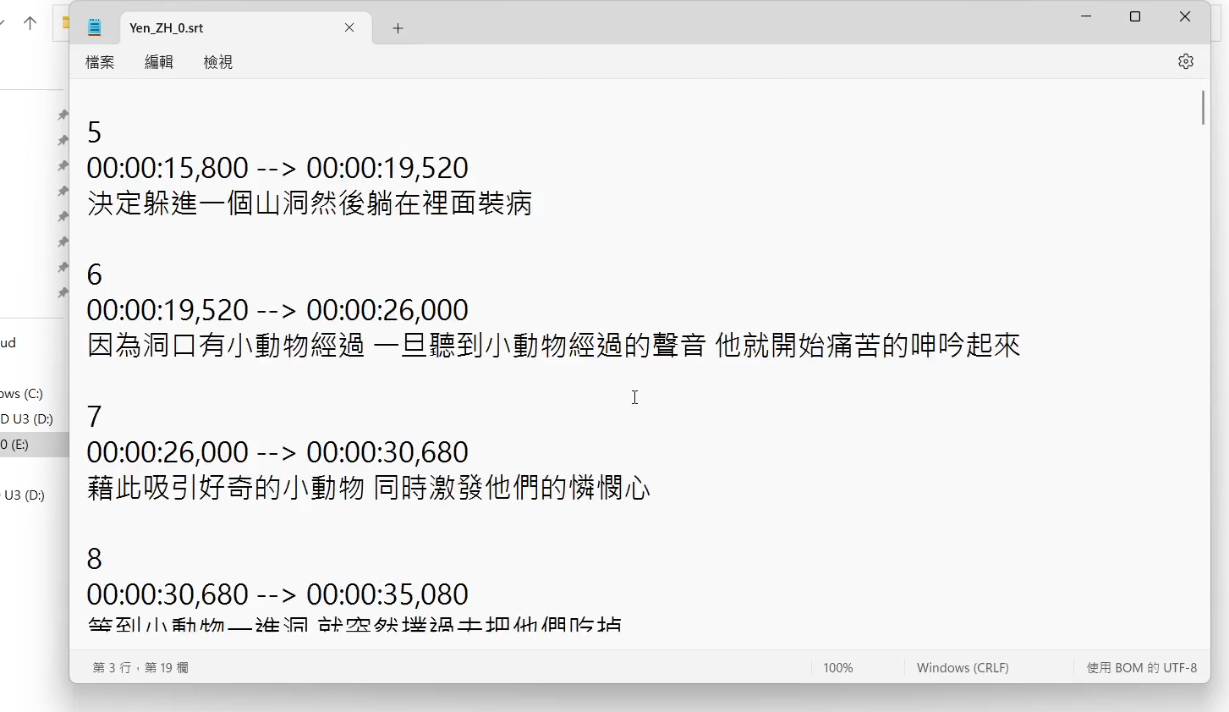
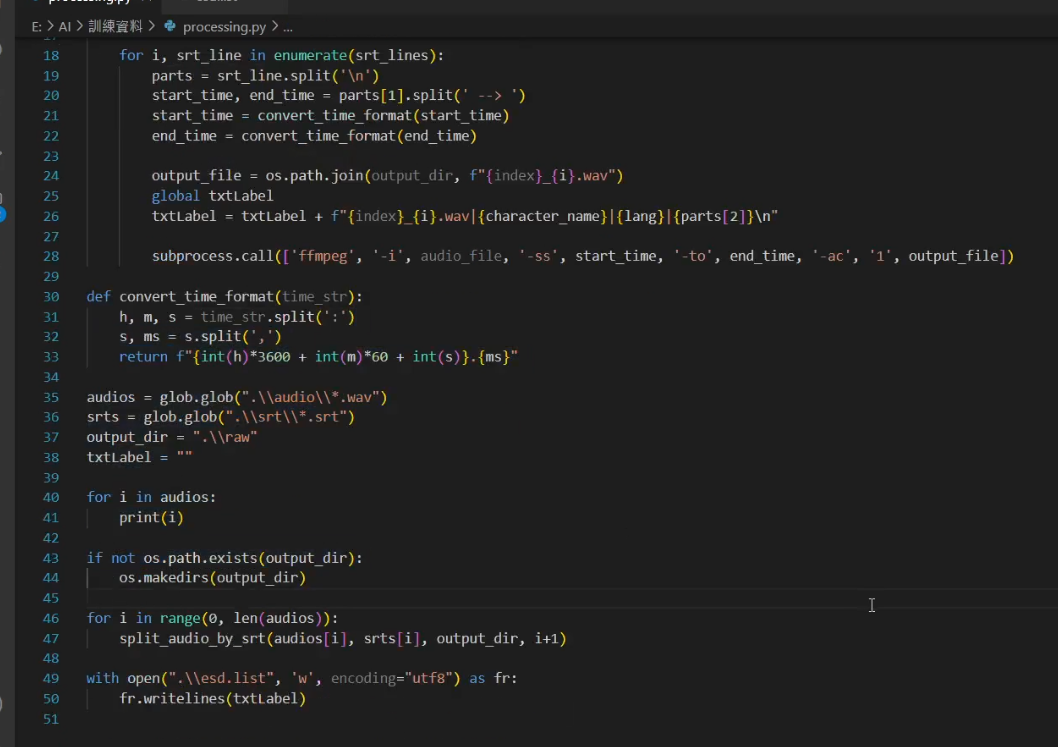
這邊我有簡單寫一個腳本,懶得自己寫的人可以直接用我寫的
processing.py
https://github.com/ADT109119/Bert-VITS2-Colab/blob/main/processing.py
我寫得腳本設定的檔案存放規則是:
|
|
檔案命名規則是 (對應的音檔與字幕取相同的名字 僅副檔名不同):
|
|
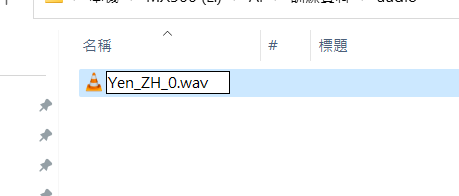
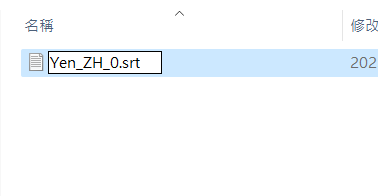
執行 processing.py 便可以得到分割好的檔案以及標記檔了
將 raw 與 esd.list 壓縮後,我們就可以進到 Colab 裡面,準備開始訓練。
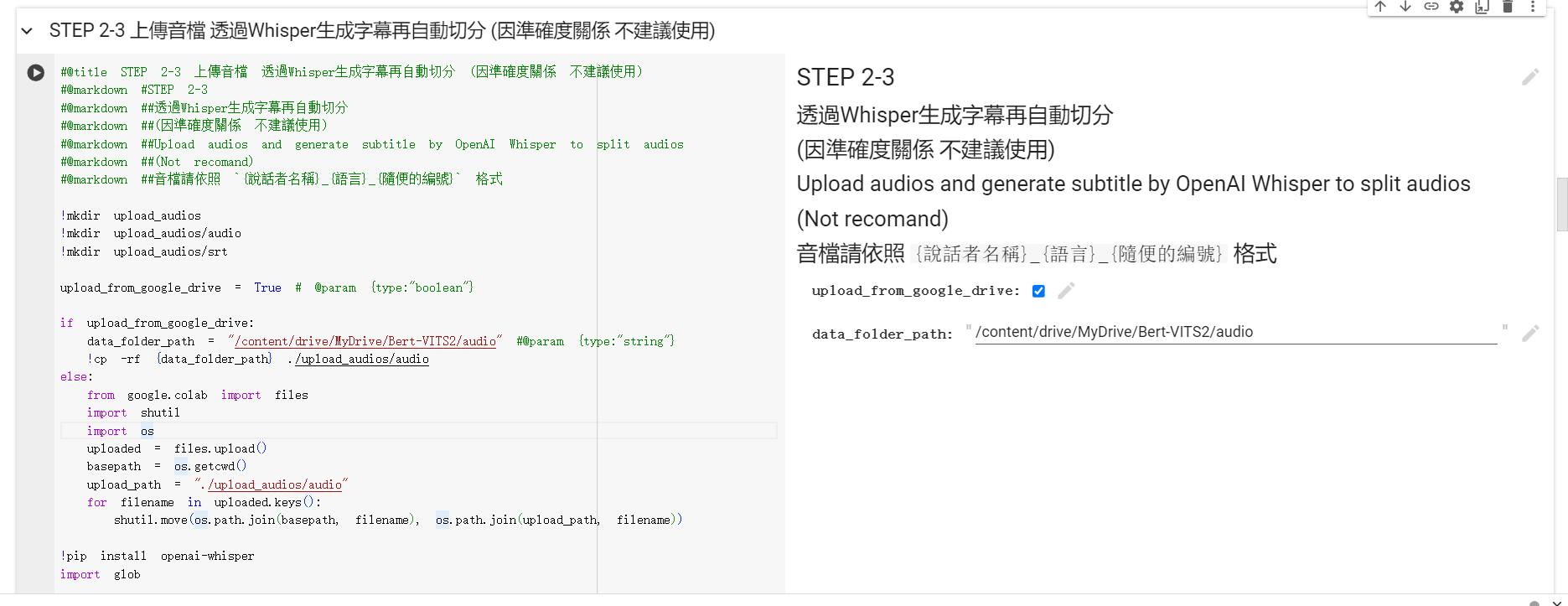
使用 Colab 內的語音辨識、分割區塊
如果要使用記事本中的語音辨識、分割區塊,這邊也還需要修改命名格式
我設定的命名規則是:
|
|
之後只需要將音檔,上傳到 Google 雲端硬碟中的 Bert-VITS2/audio 資料夾中
在執行到上傳資料集的 Colab 區塊時,執行 STEP 2-3 就可以了
在 Colab 上訓練
我們打開這個 Colab 記事本
https://colab.research.google.com/github/ADT109119/Bert-VITS2-colab/blob/main/Bert-VITS2.ipynb
確認是否連上 GPU
在裡面首先我們需要做的是先在最上方確認一下這個記事本是否連接到 GPU。如果沒有的話,要進到編輯 > 筆記本設定裡面去進行修改。
安裝函式庫以及下載 Bert 模型
確定沒問題的話,我們就可以執行 Step 1 的程式碼區塊,安裝必要的函式庫並下載 Bert 的模型。這個步驟可能會需要稍微花一點時間。 等到它安裝完函式庫以及下載完 Bert 模型後,我們就可以來上傳我們的資料集。
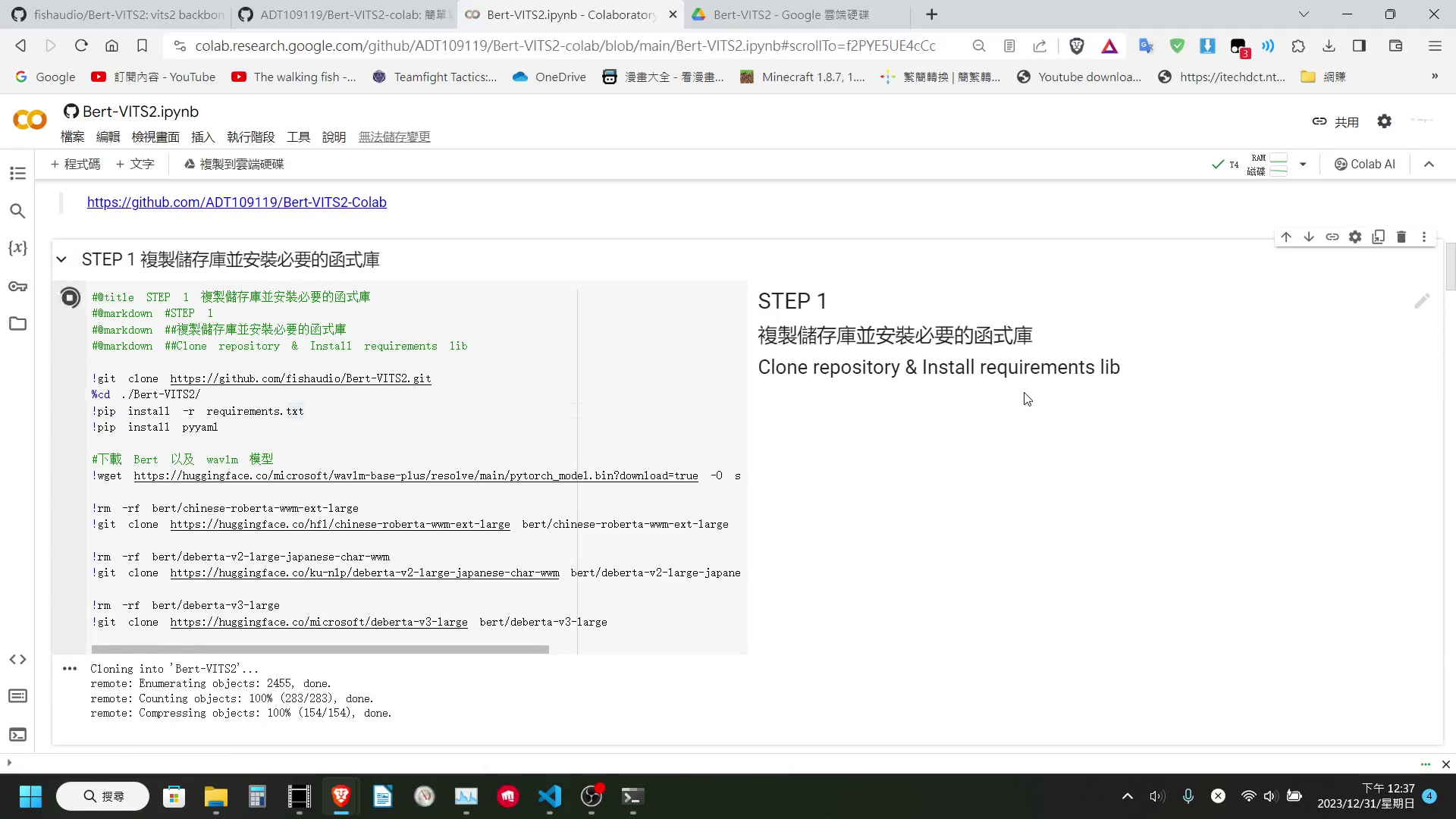
上傳資料集
這邊我有提供兩種載入資料集的方式:
- 直接生成一個上傳按鈕,然後直接上傳剛剛壓縮出來的檔案
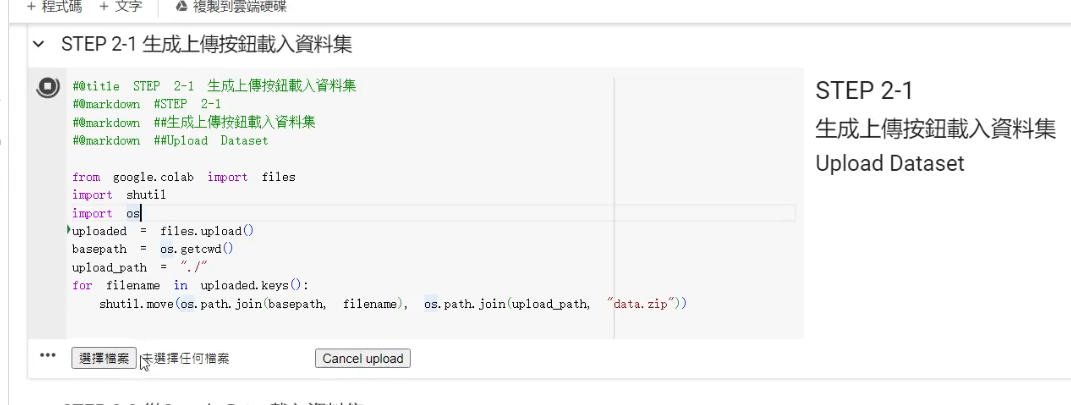
- 先上傳到 Google 雲端硬碟上,再透過 Colab 自帶的綁定(掛載) Google Drive 的功能,從 Google Drive 裡面複製檔案出來 (預設讀取 Google Drive 中的
Bert-VITS2/data.zip)
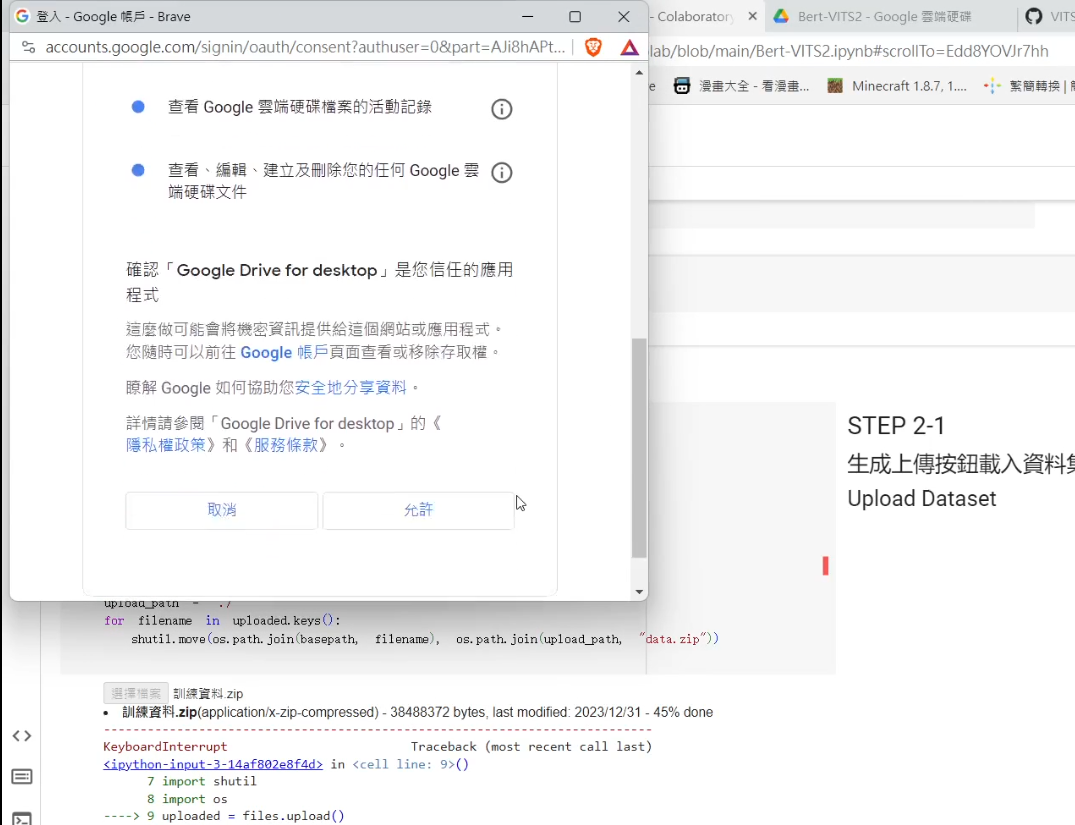
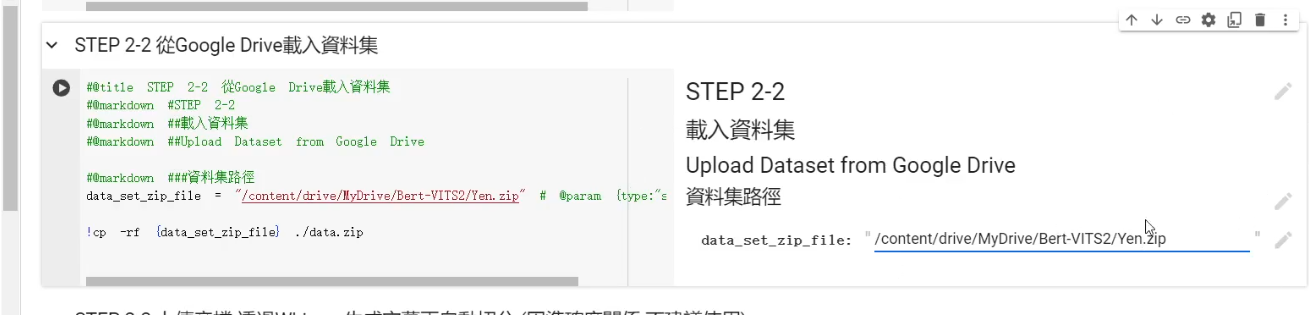
至於選用哪一個比較好,我個人會建議使用 Google Drive 來做一個中繼,會是比較好的選擇。因為直接上傳到 Colab 上的話,它的速度會非常的慢。資料集稍微大一點的話,那你可能要上傳非常久的時間。
別忘了 Colab 可是有限時的服務,你一天沒有辦法使用這個服務太久,每一分每一秒都是相當珍貴的。
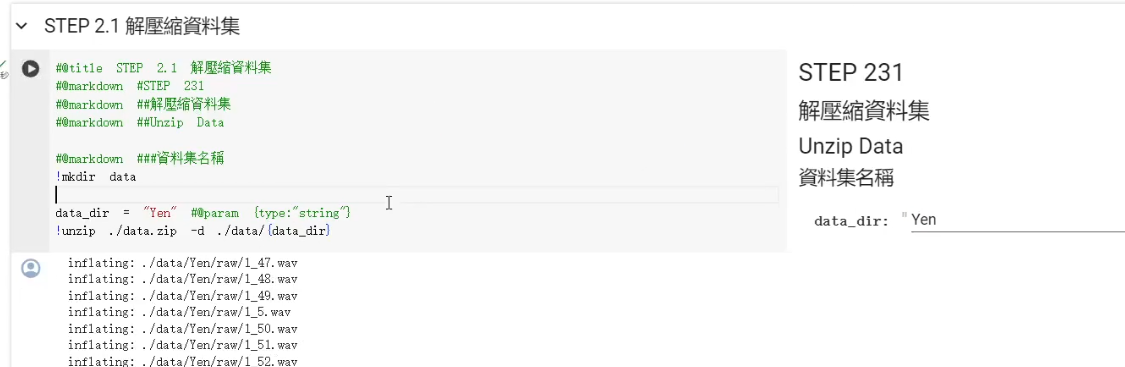
資料集名稱設定 & 解壓縮資料集
我們看到下一個區塊,這邊我們可以設定資料集的名稱。當然不調整其實也不會有什麼太大的影響,這邊我就稍微簡單調整一下,然後執行這個區塊,接著它就會將資料集加縮到對應的資料夾內。
生成設定檔
接著我們再看到下一個區塊,這個區塊基本上不用動他,直接執行即可。這個區塊會生成設定檔、對聲音重新取樣,以及生成 Bert 的標記等。
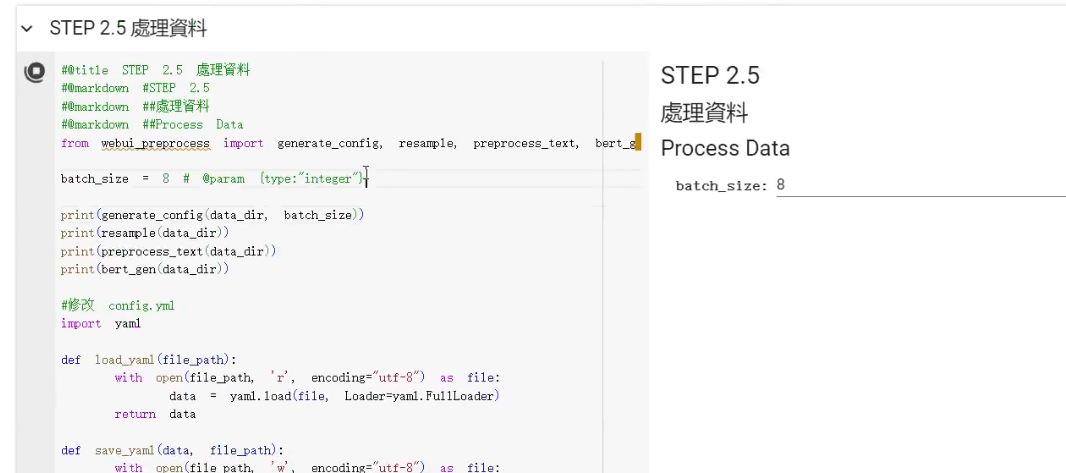
雖然說這邊我讓大家可以調訓練時的 Batch Size。但通常來說是不需要調整的。Batch Size 設 8 可以吃 14.多 GB,基本上就是可以壓在免費版 Colab 15 GB VRAM 的硬體限制邊緣。

等待它裡面的四個函式執行完成,就可以進到下一個區塊
修改自動儲存步數 (可掠過)
Config 設定檔預中設每 1000 個 Step 才會儲存一次模型,這樣並不方便我們在訓練途中使用 TensorBoard 的評估。所以這邊我們可以執行一下下面這個區塊,調整一下它自動儲存的步數。

下載預訓練模型 || 載入上次訓練到一半的模型
執行完後我們就可以進到 Step 3。這邊如果我們是第一次訓練或是想要從頭開始訓練的話,就可以點選第一個下載預訓練的模型。如果先前已經有訓練過,並且有將模型存在 Google Drive 上想要繼續訓練的,則是可以執行第二個程式碼區塊,載入上次訓練的模型。
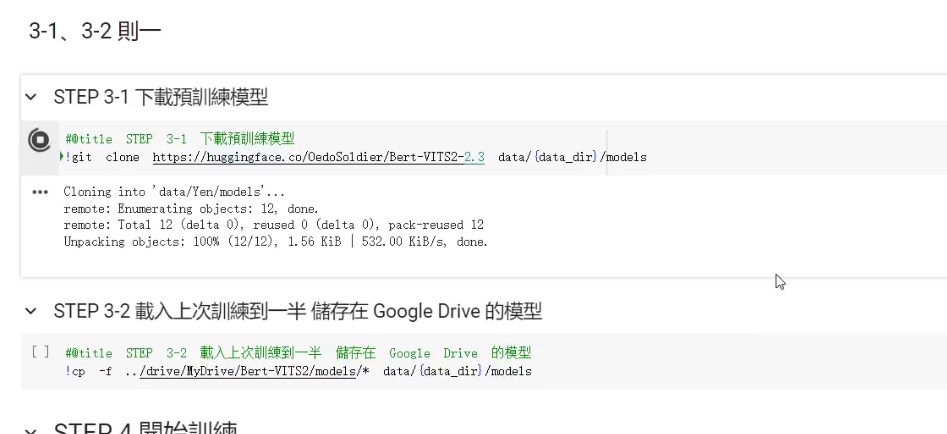
在這個區塊執行完後,我們就終於可以開始正式的訓練了!!!
開始訓練
我們執行 Step 4 的程式碼區塊,稍等一下就可以看到 TensorBoard 的啟動。
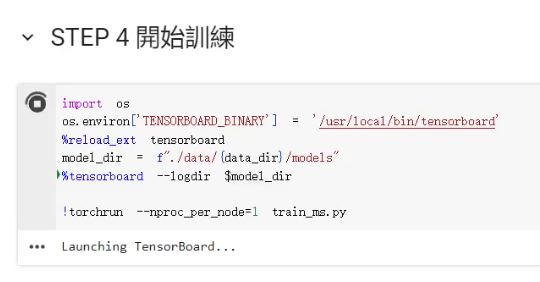
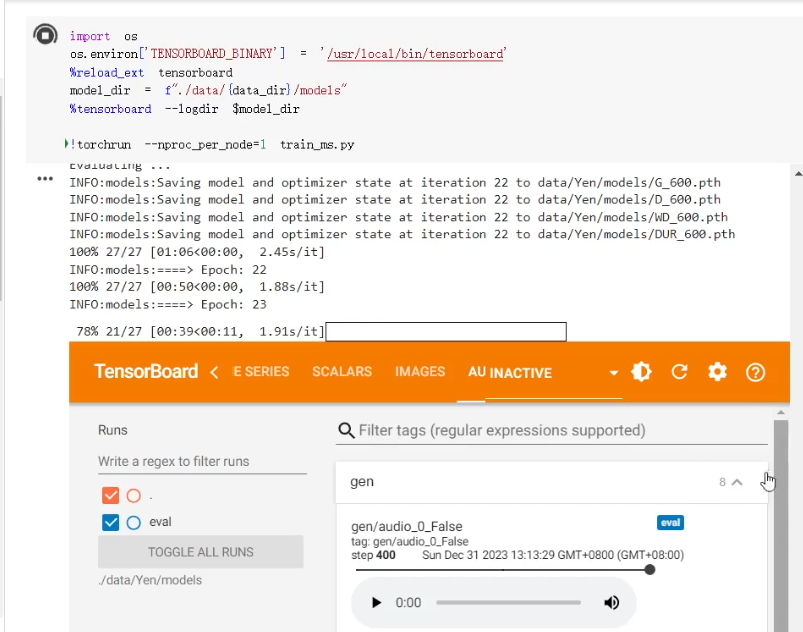
我們可以在這裡面查看目前的訓練狀況以及試聽一下目前的模型生成出來的聲音聽起來長什麼樣子。
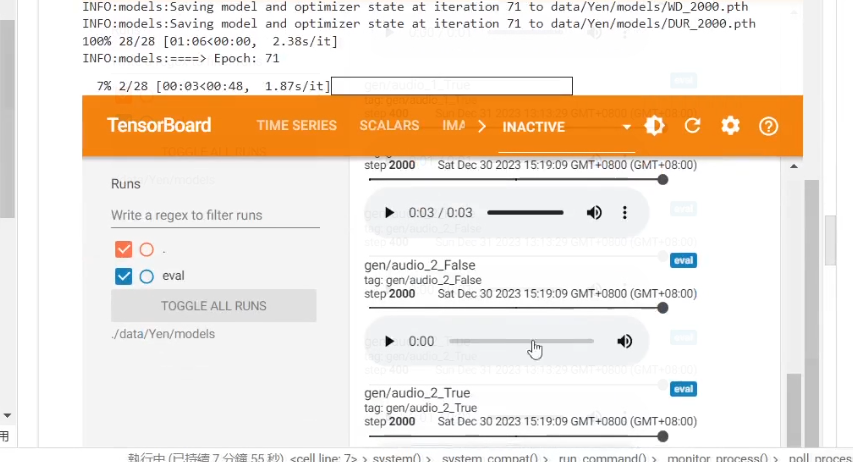
保存模型
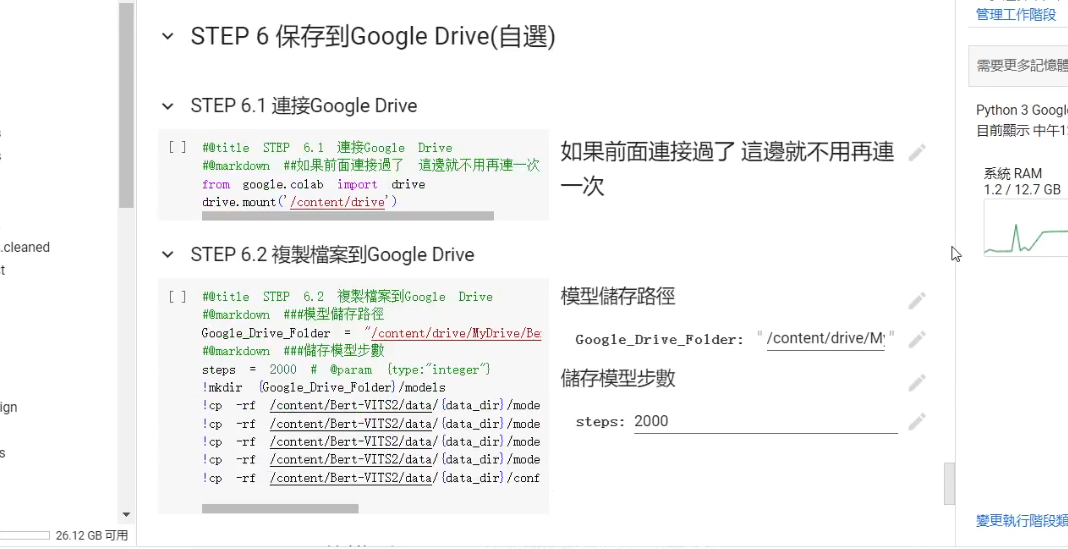
如果已經對結果滿意或者是發現模型有點 Overfitting 的話,我們就可以直接結束訓練,並到最下方下載或者是保存模型到 Google Drive 內 (需手動輸入要保存的模型步數)。
模型測試
當然在這個裡面,還是有簡單提供大家一個推理的程式區塊,只要輸入我們所想要使用的模型的 Step 數,就可以以該模型來進行推理,測試該個模型的效果。

END
以上就是本文全部的內容,如有任何問題或或是錯誤勘正,歡迎在下方留言讓我知道!

