
Anthropic 在昨日(23日)投下震撼彈,正式發布其最新一代大型語言模型 (LLM)——Claude 4,為人工智慧領域樹立了新的里程碑。此次發布的核心是兩款明星模型:Claude Opus 4 和 Claude Sonnet 4。這些新模型不僅在編碼能力、進階推理和 AI 智能體功能方面設立了業界新標準,其中 Claude Opus 4 更被譽為「全球最佳編碼模型」,直接叫板 Google 的 Gemini 2.5 Pro,誓要搶回最強 Coding 模型的頭銜。更令人興奮的是,與以往一樣,免費用戶也能夠使用到新一代的 Sonnet 模型。
Claude 4 的推出不僅是技術實力的展現,更反映了 Anthropic 針對不同市場需求的精準策略。Opus 4 以其頂尖性能和較高定價,瞄準高端企業級應用與進階開發者;而 Sonnet 4 則以親民價格和對免費用戶的開放,力求擴大市場滲透。這一雙模型策略,彰顯了 Anthropic 在 AI 智能體開發和複雜問題解決領域,尤其是在軟體工程方面,爭取領導地位的雄心。
市場背景與競爭態勢:LLM 的演進之路
大型語言模型領域正處於前所未有的高速發展期,市場對功能更強大、更智能、更具智能體能力的 AI 系統需求日益迫切。Anthropic 作為此賽道的關鍵角色,始終以其對負責任 AI 開發的承諾聞名。
值得注意的是,Claude 4 的發布緊隨 OpenAI 和 Google 等主要競爭對手推出其增強型 AI 模型之後,凸顯了 LLM 市場的白熱化競爭。這種競爭壓力無疑是技術創新的催化劑,也意味著在編碼和智能體 AI 等關鍵領域的市場領導地位是高度流動的,需要持續的卓越表現來吸引和留住用戶。
Claude 4 雙雄登場:Opus 與 Sonnet
Anthropic 於 2025 年 5 月 22 日正式推出了 Claude Opus 4 和 Claude Sonnet 4(是的,命名規則稍有改動)。這兩款模型被定位為引領編碼、進階推理和 AI 智能體新標準的核心產品,延續了過往 Claude 擅長程式設計的特點。
- Claude Opus 4:被 Anthropic 譽為「全球最佳編碼模型」及其迄今「最智慧的模型」。它專為處理複雜、長時間運行的任務和智能體工作流程而設計,旨在推動編碼、研究、寫作和科學發現的邊界。Opus 4 僅限 Claude Pro、Max、Team 等付費方案用戶及 API 調用才能使用。
- Claude Sonnet 4:作為 Claude Sonnet 3.7 的重大升級版(中階模型),Sonnet 4 在提供卓越編碼和推理能力的同時,能更精確地響應指令。它旨在為日常用例帶來前沿性能,並且對免費用戶開放,可透過 claude.ai 平台直接存取。
Opus 4 對「長時間運行的任務」和「智能體工作流程」的明確定位,以及其最大步驟數從 30 增加到 100 的變化,強烈暗示了 Anthropic 對自主 AI 智能體未來的堅定信念。模型能夠在「數千個步驟」中保持專注並「連續工作數小時」,這是實現強大智能體 AI 的基石。
突破性功能與技術進展
Claude 4 模型引入了多項關鍵技術創新,顯著提升了其性能和實用性。
1. 領先的編碼與軟體工程能力
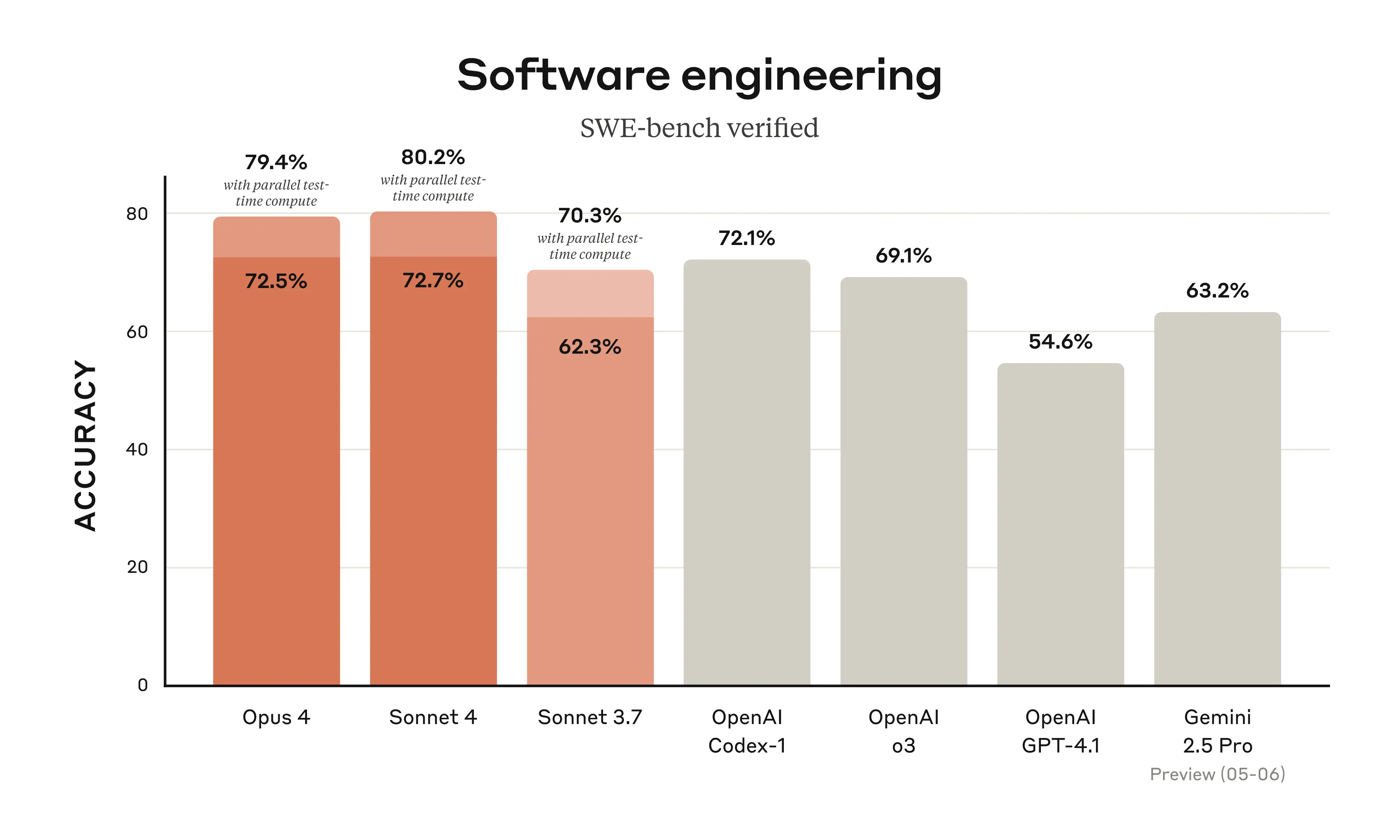
Claude 4 在編碼和軟體工程任務中展現出卓越的領導地位。根據 Anthropic 提供的測試資料(參考下方圖表),在 SWE-Bench Verify 程式能力測試中,Claude Opus 4 拿到了 72.5% (另一組數據為 79.4% with parallel test-time compute),而 Sonnet 4 也得到了 72.7% (或 80.2% with parallel test-time compute)。
為了提升開發者體驗,Claude Code 現已普遍可用,並與 VS Code 和 JetBrains 等 IDE 深度整合。GitHub 亦計劃將 Claude Sonnet 4 作為其新編碼智能體 GitHub Copilot 的核心模型。來自 Cursor、Replit、Block 等多家企業客戶的積極評價也證實了 Claude 4 在編碼和複雜程式碼庫理解方面的強大能力。
2. 進階推理與智能體 AI
Claude 4 在推理和智能體 AI 方面實現了質的飛躍。Opus 4 和 Sonnet 4 作為混合模型,支援即時回應和用於更深層次推理的「擴展思考」兩種模式,分別可用於需要即時回應或是想要解決複雜問題的場景。
此外,它們還具備並行工具執行能力,能同時使用多個工具。例如,可以同時呼叫多個 API 一次獲取多個來源的商品價格,或者一次性呼叫今日的天氣、新聞、股價等進行彙整,而不用一個個接著呼叫。記憶能力也得到顯著提升,例如 Opus 4 能在玩 Pokémon 遊戲時記錄筆記並持續遊戲 24 小時。
「擴展思考」、「並行工具執行」、「增強記憶」以及「增加最大步驟數」的結合,代表了邁向真正自主且可靠的 AI 智能體的重要協同飛躍。值得注意的是,Anthropic 簡化了工具腳手架,表明核心模型已更有效地內化規劃能力。
3. 針對開發者的新 API 功能
Anthropic 為開發者提供了四項新的 API 功能:程式碼執行工具、MCP 連接器、Files API 和最長一小時的提示緩存功能。同時發布了可擴展的 Claude Code SDK,使開發者能夠構建自訂智能體。
效能基準與競爭力分析
Claude 4 模型在多個關鍵性能指標上展現出強勁實力。
關鍵性能指標與比較
如下方 Anthropic 提供的基準測試表所示,Claude Opus 4 和 Sonnet 4 在多項編碼相關的基準測試中表現突出。例如在 SWE-bench Verified 中,Opus 4 (with bash/editor tools) 達到 72.5%,Sonnet 4 (with bash/editor tools) 達到 72.7%。若採用平行測試時間計算 (parallel test-time compute),分數更高達 79.4% 和 80.2%。這遠超 GPT-4.1 (54.6%) 和 Gemini 2.5 Pro (Preview 05-06) (63.2%),甚至優於 OpenAI o3 (69.1%)。在測試代理工具調用能力的 TAU-bench (Airline) 中,Claude 4 系列也是大獲全勝。
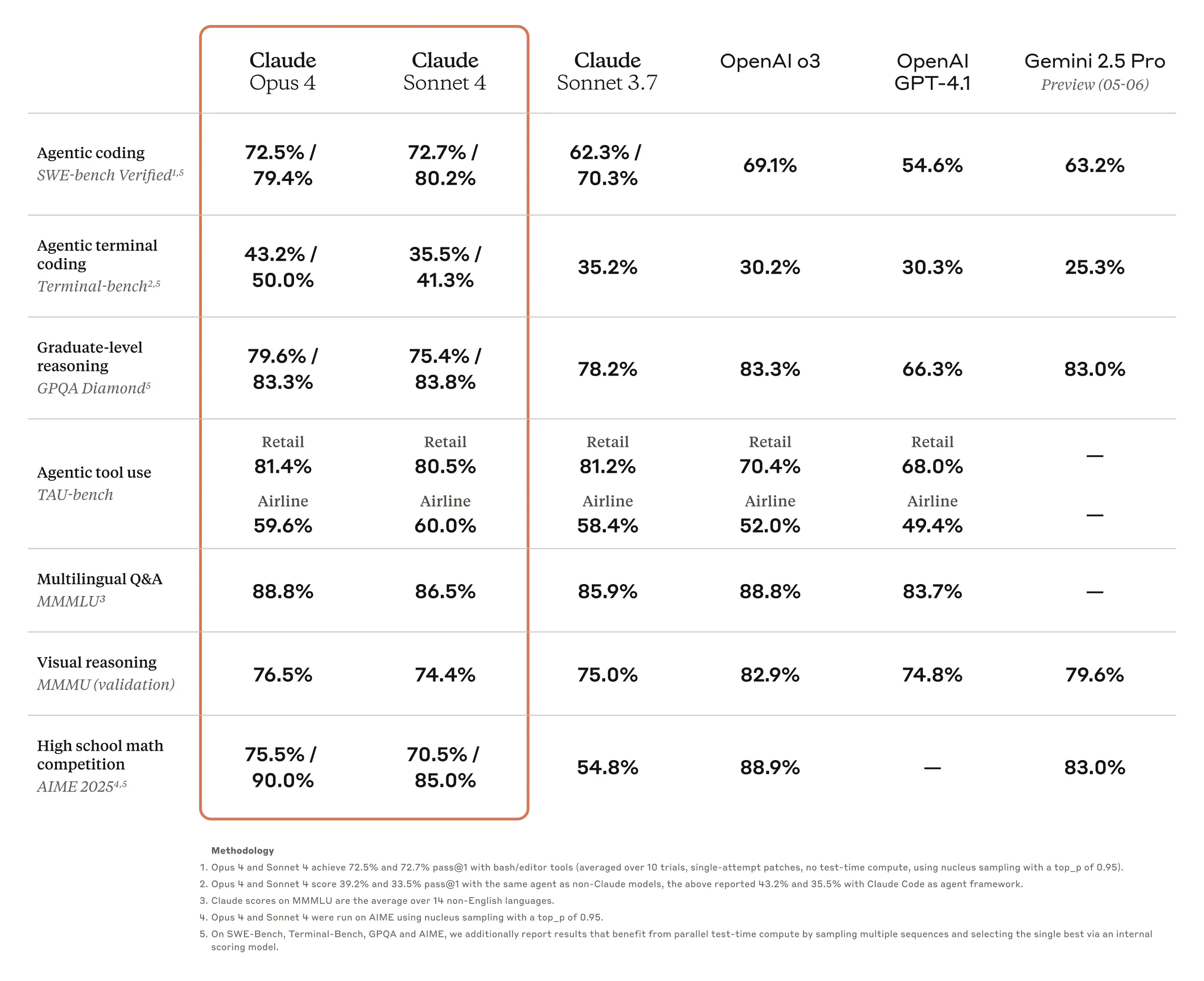
然而,若將目光投向程式以外的領域,Claude 4 系列的表現則不那麼亮眼。在測試科學能力的 GPQA Diamond 中,Claude 4 系列(Opus 4: 79.6%/83.3%, Sonnet 4: 75.4%/83.8%)僅略勝於 GPT-4.1 (66.3%),但落後於 Gemini 2.5 Pro (83.0%) 和 OpenAI o3 (83.3%)。在視覺推理的 MMMU (validation) 和數學能力的 AIME 2025 測試中,Claude 4 系列的表現也相對一般。
儘管官方基準測試描繪了 Claude 4 的強大表現,但 Reddit 社群的討論卻揭示了基準測試性能與實際用戶體驗之間可能存在的差異,尤其是在創意寫作任務方面。這表明模型在可量化領域表現出色,但在更主觀任務中的表現可能仍有提升空間。
上手 Claude 4:可用性與定價
Claude 4 模型已透過多個平台廣泛提供,並採用了明確的定價策略。
Opus 4 和 Sonnet 4 均可透過 Anthropic API、Amazon Bedrock 和 Google Cloud 的 Vertex AI 存取。Opus 4 供給 Claude 的 Pro、Max、Team 和 Enterprise 用戶。Sonnet 4 則向免費用戶開放,可直接透過 claude.ai 聊天介面存取。兩款模型的 Context Window 大小皆維持在 200K tokens。
Claude 4 的 API 定價與之前的 Opus 和 Sonnet 模型保持一致:
- Opus 4 API:每百萬輸入 token 成本為 15 美元,輸出 token 成本為 75 美元。
- Sonnet 4 API:每百萬輸入 token 成本為 3 美元,輸出 token 成本為 15 美元。(Opus 4 是 Sonnet 4 的 5 倍價格)
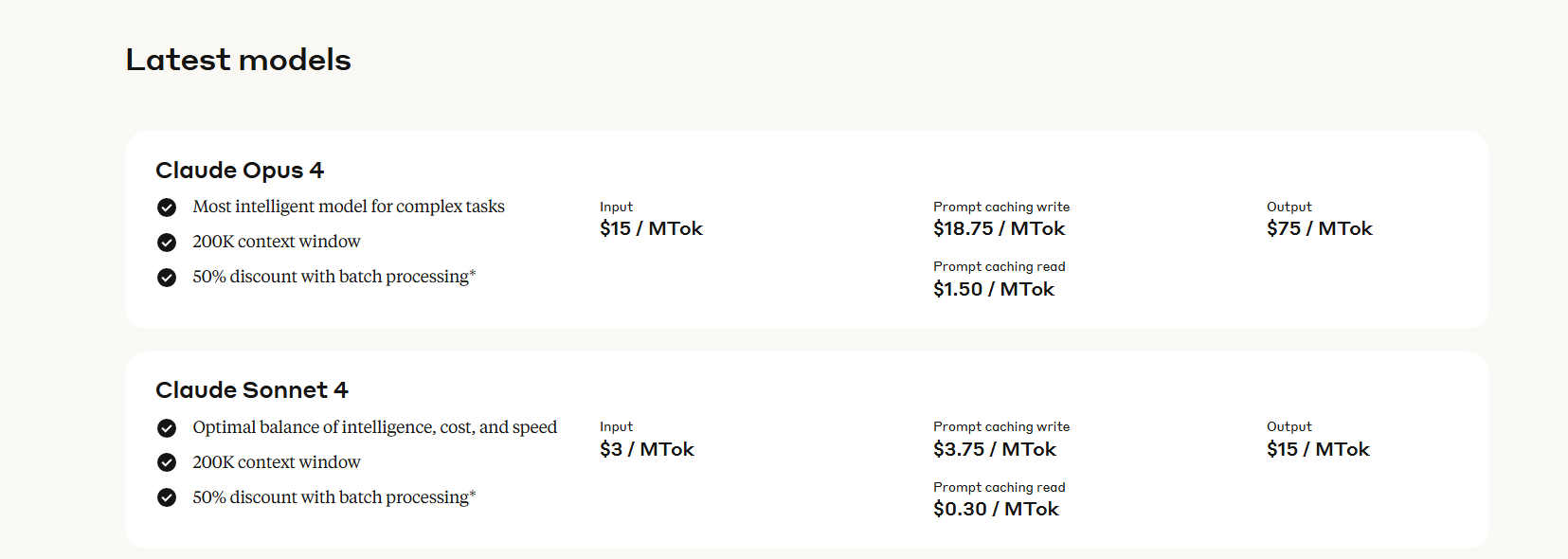
Anthropic 也提供了詳細的緩存定價。儘管單價不變,但由於擴展思考和多步驟過程導致的 token 使用量增加,複雜智能體任務的總成本可能會大幅上升。開發者在優化成本和性能時,必須仔細管理其「思考預算」。
Claude Sonnet 4 實測體驗分享
接下來,讓我們實際體驗一下免費版的 Claude Sonnet 4 在程式能力方面的表現如何。
1. 網頁 Landing Page 生成
首先,我嘗試讓 Sonnet 4 製作一個關於 Claude 4 發布的介紹頁面。由於免費版聊天介面不支援網路搜尋,初次生成的網頁內容有些稀少,儘管介面設計尚可。
於是,我提供了使用 Gemini DeepResearch 整理的 Claude 4 發布訊息,再請它製作 Landing Page。這次開頭看起來還行,但越往下滑越顯單調,在較寬的桌面版網站上表現更差。
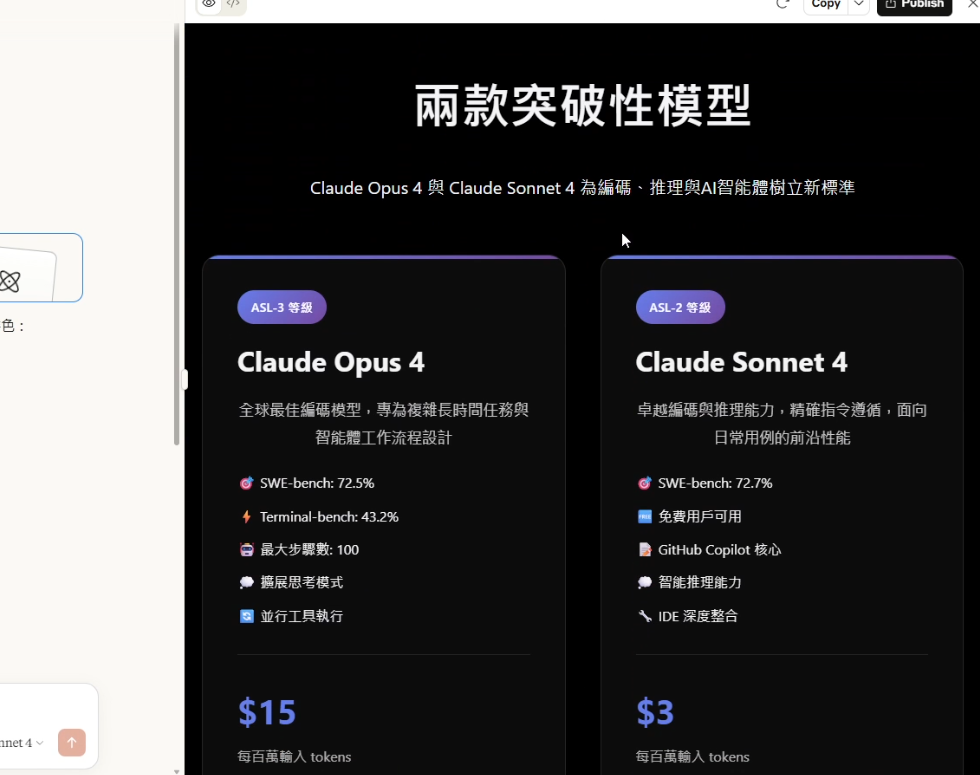
作為對比,我使用相同的提示詞(附帶整理好的訊息)讓 Google AI Studio 中的 Gemini 2.5 Pro 生成。整體效果明顯優於 Claude Sonnet 4。
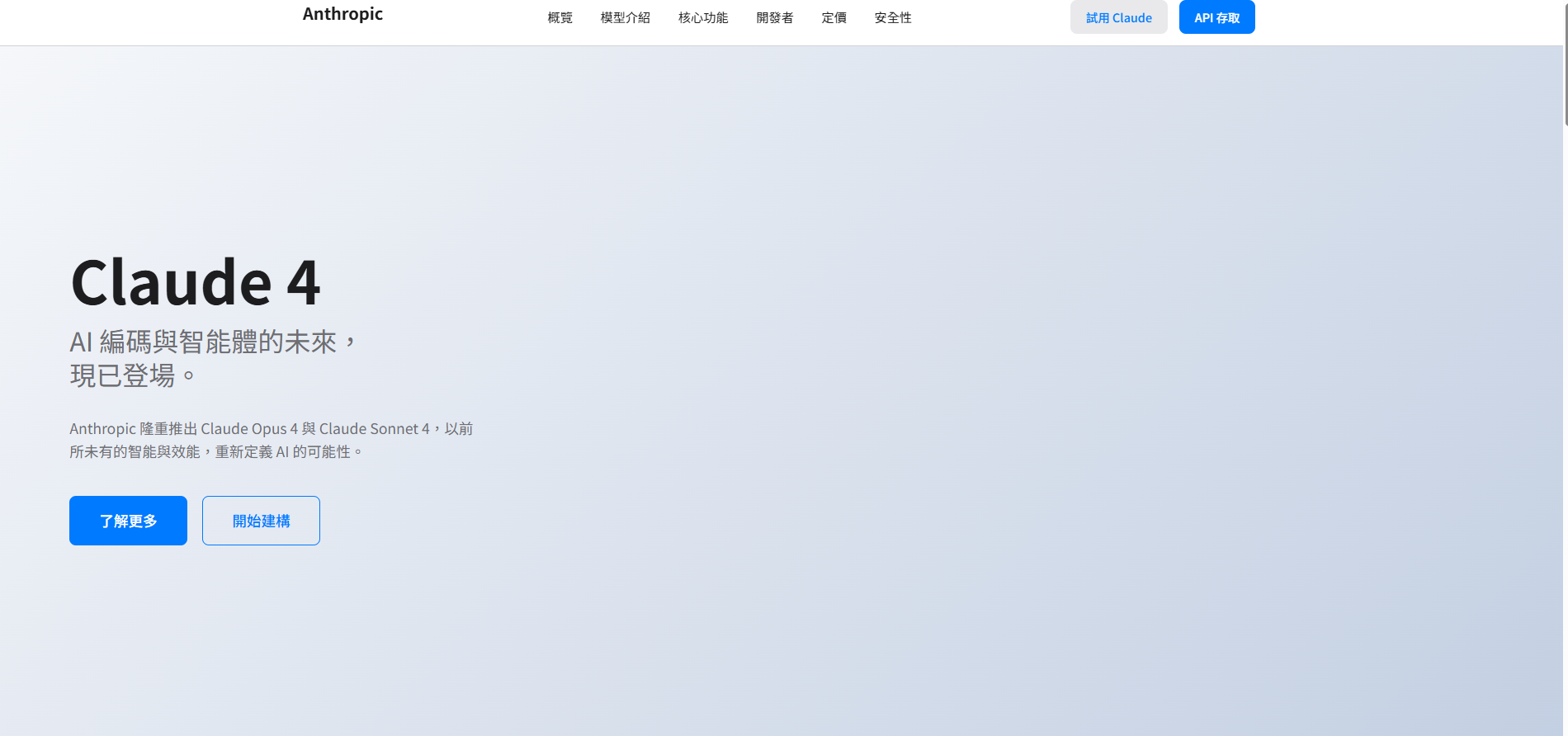
當然,提示詞的詳細程度影響很大。當我提供一個更詳細的提示詞後(雖然忘了附上 Claude 4 的詳細發布內容,導致網頁偏短),Sonnet 4 生成的網頁效果還算不錯。
Demo 網頁 - 重新生成 (此版本有在經過多一次對話微調)

初步結論:在網頁生成方面,Claude Sonnet 4 與 Gemini 2.5 Pro 生成的效果差異可能不大,關鍵更多在於使用者輸入提示詞的質量和設計理解。懂設計、會提問的使用者,更有可能生成美觀的網頁,或透過多輪對話調整至理想狀態。
值得一提的是,有開發者在 X 平台上展示了使用 Claude Opus 4 製作出充滿特效的廣告頁面,效果驚人,但不確定同樣的提示詞在 Sonnet 4 上的表現如何。
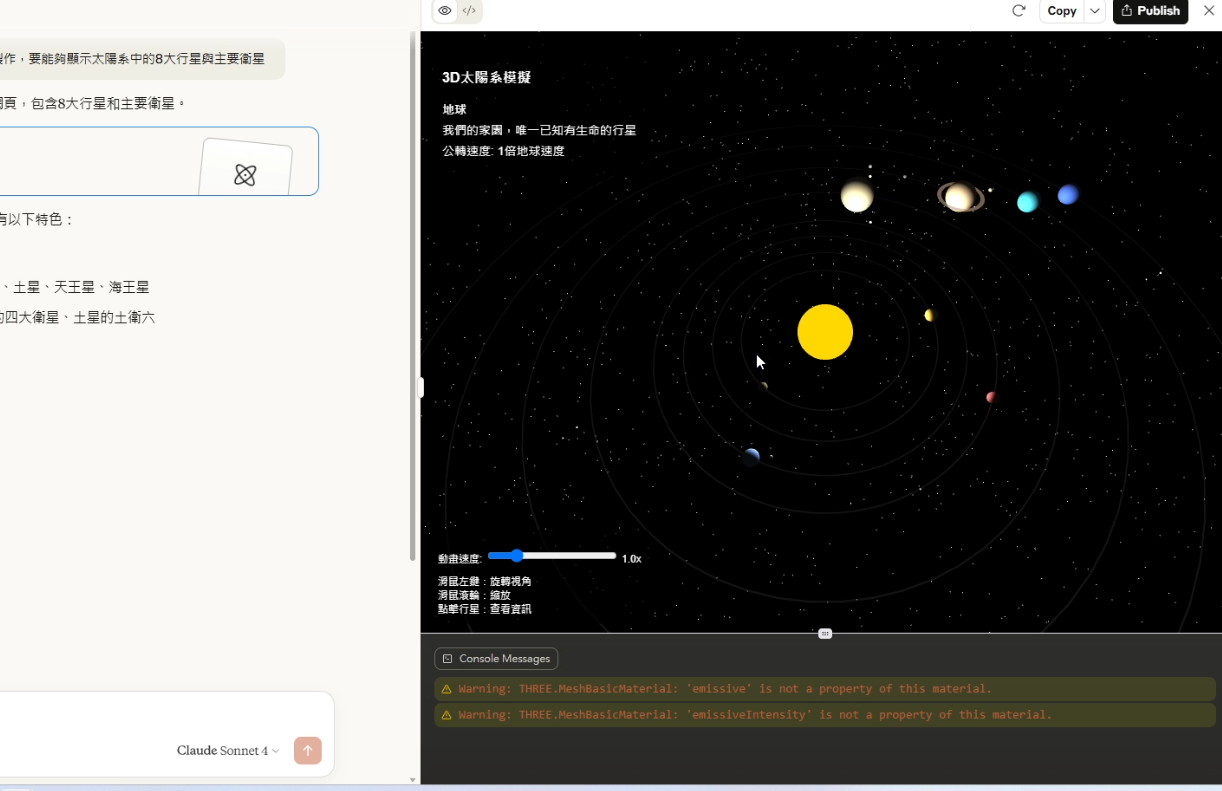
2. 複雜程式碼生成:Three.js 太陽系模擬
接下來,我讓 Sonnet 4 使用 Three.js 製作一個太陽系模擬網頁,要求生成八大行星及主要衛星。稍等片刻,它生成的效果非常好,而且一次就成功了!同樣的提示詞在 Gemini 上有時可能還需要微調。
3. p5.js 物理模擬:六角形內彈跳小球
按照慣例,我測試讓 Sonnet 4 生成一個 p5.js 程式:一個六角形,裡面有一顆球在彈跳。 第一次生成時,結果少了一個函式,無法正常運行。我直接讓它重跑一遍,這次的結果還算不錯,球的彈跳大致真實,有受到重力和摩擦影響。但有個小瑕疵:當六角形將球稍微抬起時,球似乎碰撞到什麼東西提早彈了起來,略顯詭異。

4. Python 物理模擬:六角形內彈跳小球
換成 Python 程式,情況又有所不同。下載並運行生成的 Pygame 程式後,球的物理狀況非常詭異,基本上球幾乎都會順著六邊形轉動的方向,在明明還沒有開始傾斜前就先滑過去。 但要說 Sonnet 4 的生成效果不好,其實也不然。因為 Gemini 2.5 Pro 生成出來的效果也算是半斤八兩。至少它們生成的球有碰到牆壁產生反彈效果,有些模型可能連牆壁都碰不到。

5. 圖片辨識能力
最後,測試一下 Sonnet 4 的圖片辨識能力。我使用了之前測試 Gemini 2.5 Pro 時用過的一張包含手寫公告的圖片。很可惜,Sonnet 4 依舊沒有辦法辨識下方那排手寫文字,如果直接問他那排字是什麼,它會隨便亂掰。

實測小結
個人感覺 Claude Sonnet 4 的表現在程式碼生成方面算是還不錯,可能稍微優於 Gemini 2.5 Pro,但差距沒有到太大。而 Gemini 2.5 Pro 依舊有其優勢,例如其超大的 Context Window(目前可達1M,未來甚至2M)以及相對便宜的 API 價格。 當然,若搭配一些輔助工具如 Cursor、Cline 等,使用體驗應該會更好,因為這些工具內建了針對開發場景優化過的提示詞。
安全至上:Anthropic 的承諾
Anthropic 一直將 AI 安全性置於其開發工作的核心。
AI 安全等級 (ASL) 指定
Claude Opus 4 被歸類為 ASL-3 標準,而 Claude Sonnet 4 則為 ASL-2 標準。ASL 的確定涉及內部和外部的安全測試。
負責任擴展的承諾
Anthropic 根據其負責任擴展政策對 Claude 4 進行了廣泛的部署前安全測試。特別值得關注的是,Opus 4 在 CBRN(化學、生物、放射、核)相關評估中展現出「實質性更強的能力」,這導致其被指定為 ASL-3。Anthropic 正在「啟動 AI 安全等級 3 保護」,並透過「新的錯誤懸賞計畫測試其安全防禦措施」。
Opus 4 被明確指定為 ASL-3,凸顯了 Anthropic 在識別和緩解與高度強大 AI 相關風險方面的積極態度,這在競爭激烈的 AI 環境中是一個關鍵的差異化因素。
業界迴響與社群聲音 (除上述實測外)
Claude 4 發布後,除了上述個人實測,業界和社群對其初期影響表現出混合的評價。
主要客戶評價與早期採用趨勢
業界對 Claude 4 的反響普遍積極,特別是在其編碼和智能體能力方面。GitHub 計劃將 Sonnet 4 用於其新的編碼智能體。來自 Cursor、Replit、Databricks、Snowflake 等公司的客戶提供了強烈背書,讚揚其在編碼、複雜程式碼庫理解、多文件修改、調試和智能體推理方面的表現。
初期用戶回饋與感知限制 (Reddit 等社群)
然而,Reddit 上的討論顯示了用戶對 Claude 4 的評價褒貶不一。一些用戶對 Opus 4 在創意寫作方面的表現「不太滿意」,指出存在截斷內容、粗心錯誤等問題。另一位用戶則對其創意寫作表現「完全失望」,認為它在一致性方面存在問題。此外,也有用戶對基準測試的透明度和「蘋果對蘋果」比較提出質疑。
業界的熱烈讚譽(主要集中在編碼和智能體任務)與社群中一些負面回饋(特別是在創意寫作方面)之間的差異,揭示了 LLM 開發中的一個關鍵挑戰:針對一個領域的優化可能會無意中影響其他領域的性能。
戰略意義與未來展望
Claude 4 的發布對 AI 產業產生了深遠的戰略影響。
對 AI 智能體開發與企業解決方案的影響
Claude 4 對智能體 AI 的強調,使其成為構建更複雜、更自主的 AI 智能體的關鍵推動者。可擴展的 Claude Code SDK 進一步加速了這項進程。來自 Databricks 和 Snowflake 等客戶的評價也突顯了其在企業數據推理方面的巨大潛力。
LLM 市場中的潛在挑戰與機遇
Claude 4 的推出帶來了顯著的機遇和挑戰。機遇在於其強大的編碼和智能體性能有望佔據重要市場份額。分層模型方法擴大了市場覆蓋。然而,挑戰依然嚴峻,與 OpenAI 和 Google 的競爭異常激烈。平衡不同任務(如編碼與創意寫作,或如實測中不同程式語言的細微表現差異)的性能仍是難題。
Anthropic 透過大力推動智能體 AI 和編碼,並對 AI 安全等級採取透明態度,表明其戰略性地嘗試不僅在原始性能上,更在負責任創新方面實現差異化。
總結
Claude 4 的發布是大型語言模型領域的一項重大進步。特別是 Claude Opus 4,在編碼和智能體 AI 方面樹立了新的基準。這些技術進步使得 Claude 4 能夠處理更複雜、更長時間的任務。
從實際測試來看,Claude Sonnet 4 在其擅長的程式碼生成領域確實表現不俗,很多情況下能與 Gemini 2.5 Pro 並駕齊驅,甚至在某些特定任務(如一次性成功生成複雜的 Three.js 程式)上略勝一籌。然而,在非編碼領域如視覺理解,或某些特定程式物理模擬的細節上,仍有提升空間。它與 Gemini 2.5 Pro 各有千秋,使用者可以根據自己的需求和預算進行選擇。




















