近年 AI 熱潮的興起,因為模型的訓練需要大量的資料,獲得這些資料最簡單的方法,就是從網路上抓。這使得更多人開始注意自身作品、發文的著作權問題,「自己的作品是否被未經同意的拿來訓練AI」、「公司透過我們的資料訓練模型獲利是否該分錢」等。
近期 OpenAI 公布了官方的網路爬蟲 —— GPTBot,幾乎就等同於承認了,未來 GPT-5 等模型,會使用網路資料來訓練。
根據 OpenAI 所述:
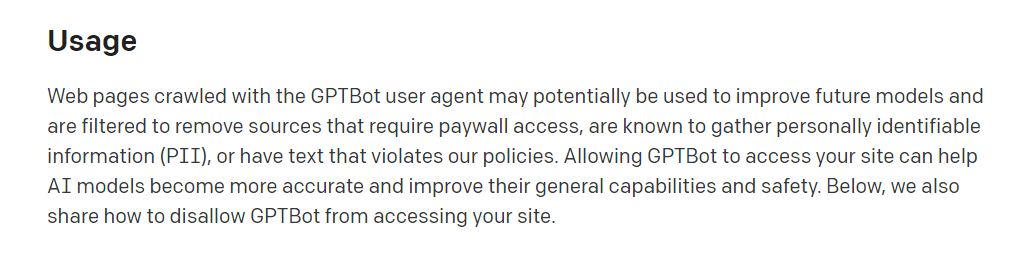
使用 GPTBot 使用者代理程式爬取的網頁,有可能被用來改善未來的模型,並且經過篩選以移除需要付費閱覽權限、已知收集個人身份識別資訊(PII)或含有違反我們政策的文字的來源。允許GPTBot存取您的網站可以協助AI模型變得更準確,並改善其一般能力與安全性。以下也會分享如何禁止GPTBot存取您的網站。
基本上還算是有一點良心,願意允許大家禁止爬蟲訪問。
如何禁止 GPTBot 抓取網站
要禁止 GPTBot 訪問,我們首先要先知道它的 User-Agent,並將其加入網站的 robots.txt 內,決定是要整個禁止,或是部分禁止。
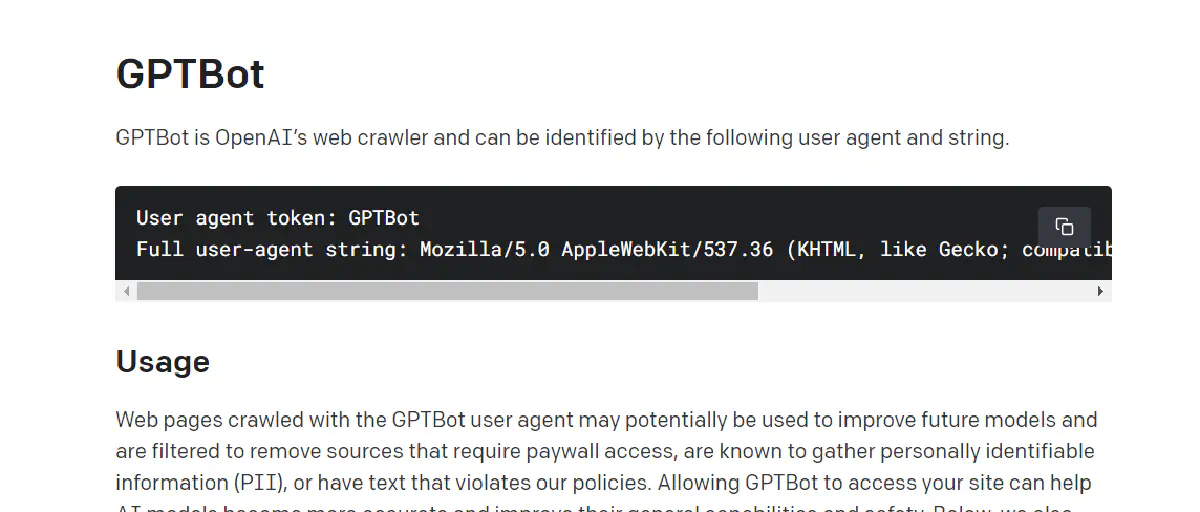
GPTBot 的使用者代理字串(User-Agent String)
以下是 GPTBot 的 User-Agent:
|
|
禁止 GPTBot 抓取整個網站
如果要禁止 GPTBot 抓取整個網站,我們需要在 robots.txt 內貼上以下字串,禁止爬蟲訪問所有目錄:
|
|
禁止 GPTBot 抓取部分路徑
如果只要禁止 GPTBot 抓取網站部分位置,我們可以將 robots.txt 的設定改成以下字串:
|
|




















