
AI 領域的熱度持續延燒,Meta 在 23 號晚上發表了 Llama 3.1 系列模型,包含 8B、70B 以及先前預告過的 400B+ 參數模型。Llama 3.1 發布的 405B 參數模型,根據 Meta 官方數據,其效能甚至略微勝過 GPT-4o,令人相當期待!

Llama 3.1 重點更新
Context Window 大升級
Llama 3.1 將 Context Window 大小從 8K tokens 提升至 128K tokens,解決了處理長文摘要和長對話的限制。
模型架構與技術
Llama 3.1 維持 Llama 3 的架構,即使是 405B 參數模型也採用標準 decoder-only transformer 架構,並未使用混合專家模型。同時,Llama 3.1 繼續使用 GQA(分組查詢注意力)技術,搭配擴展後的 Context Window 大小,更適合處理會議或文章摘要(訊息來源: Hugging Face 官方部落格)。

Llama 3.1 效能評比
405B 模型:開源模型之最
Meta 將 Llama 3.1 405B 模型與 GPT-4、GPT-4o、Claude 3.5 sonnet 等模型進行比較,結果顯示 Llama 3.1 在 GSM8K、ARC Challenge、Multilingual MGSN 等測試資料集上表現優於 GPT-4o 和 Claude 3.5 sonnet。
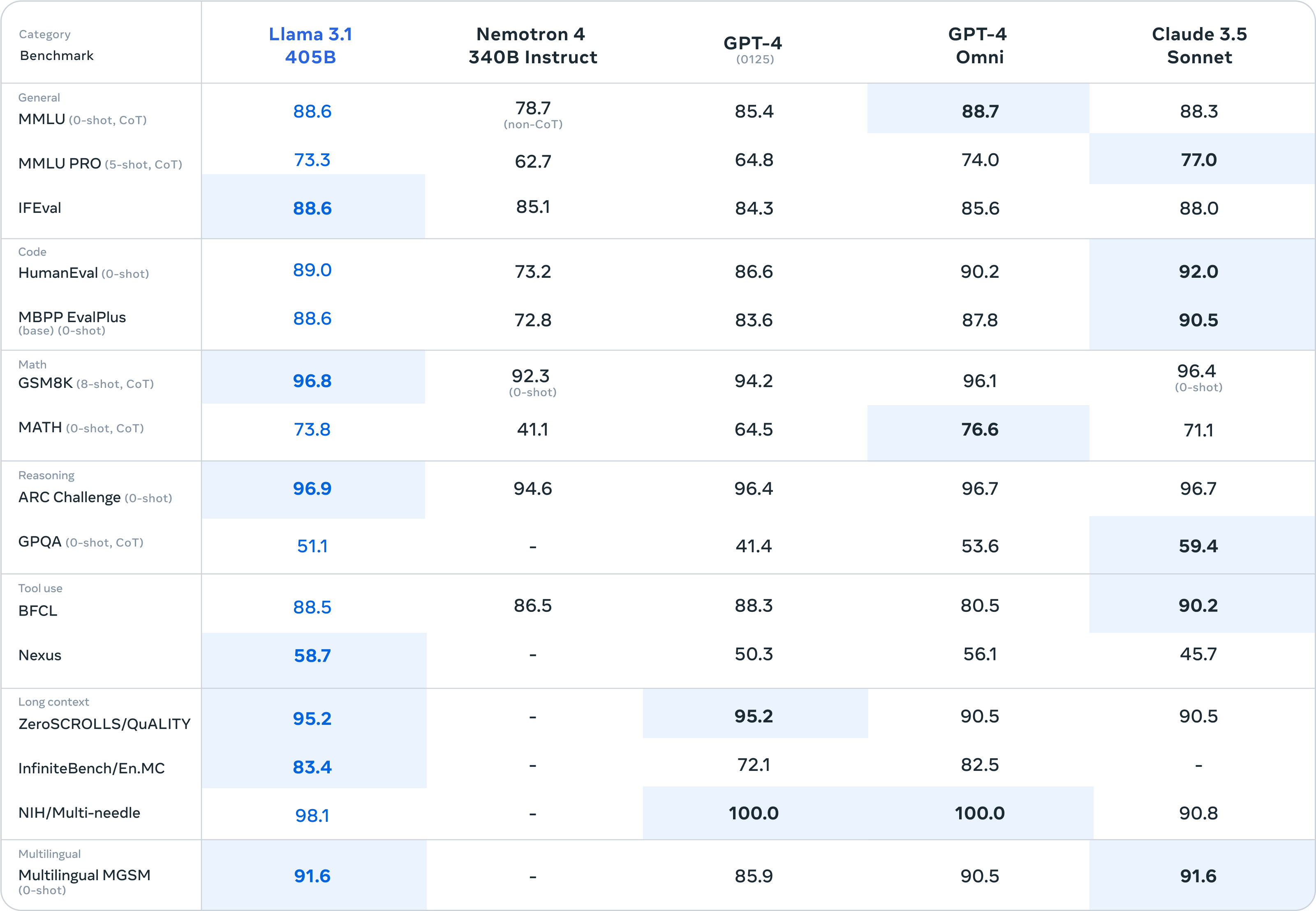
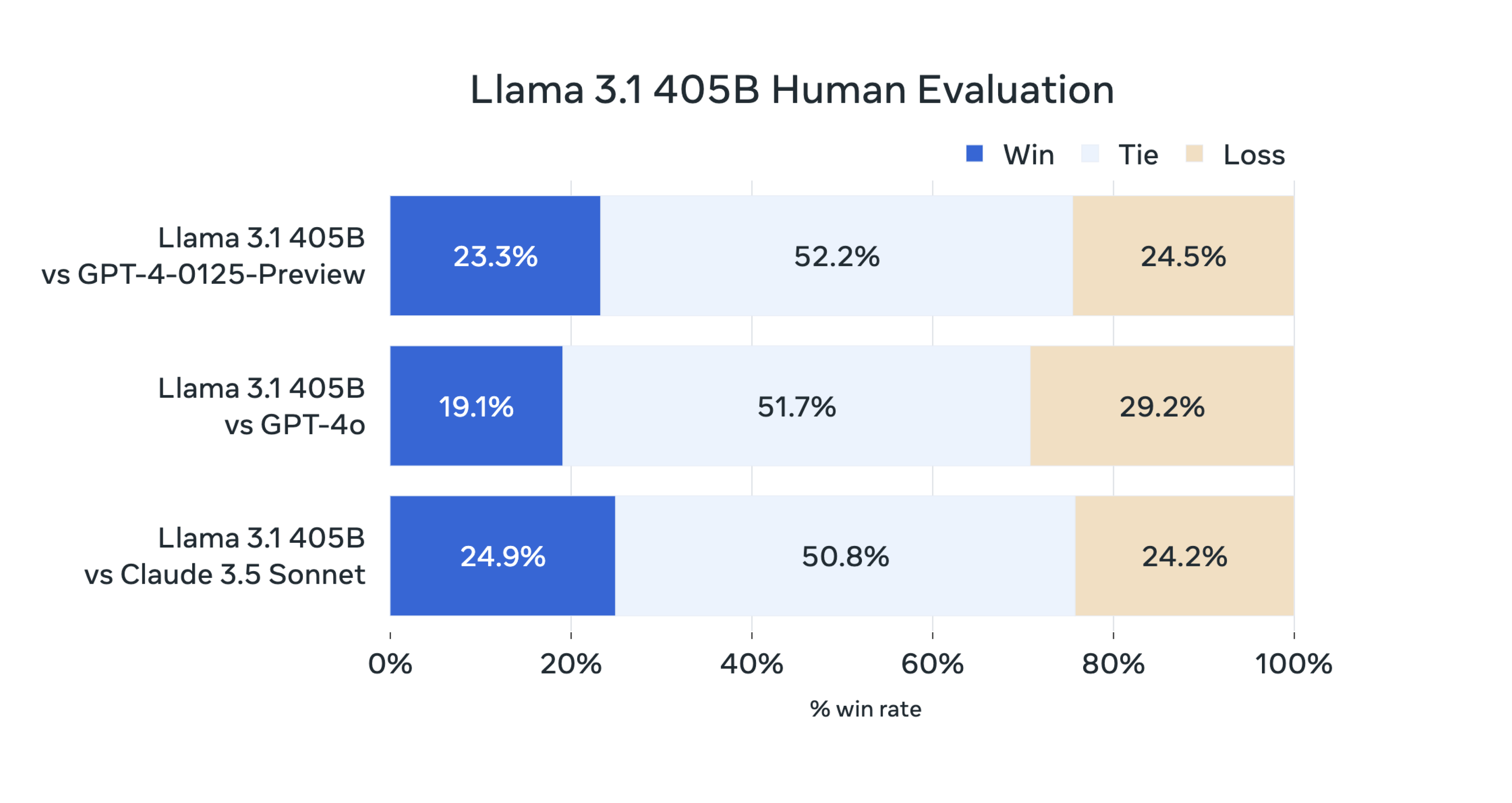
雖然在 MMLU、Human Eval、MATH 等測試資料集表現略遜於閉源模型,但分數差距不大。此外,人工評估結果顯示,Llama 3.1 405B 模型的輸出表現與 GPT-4 和 Claude 3.5 Sonnet 相當,略遜於 GPT-4o。
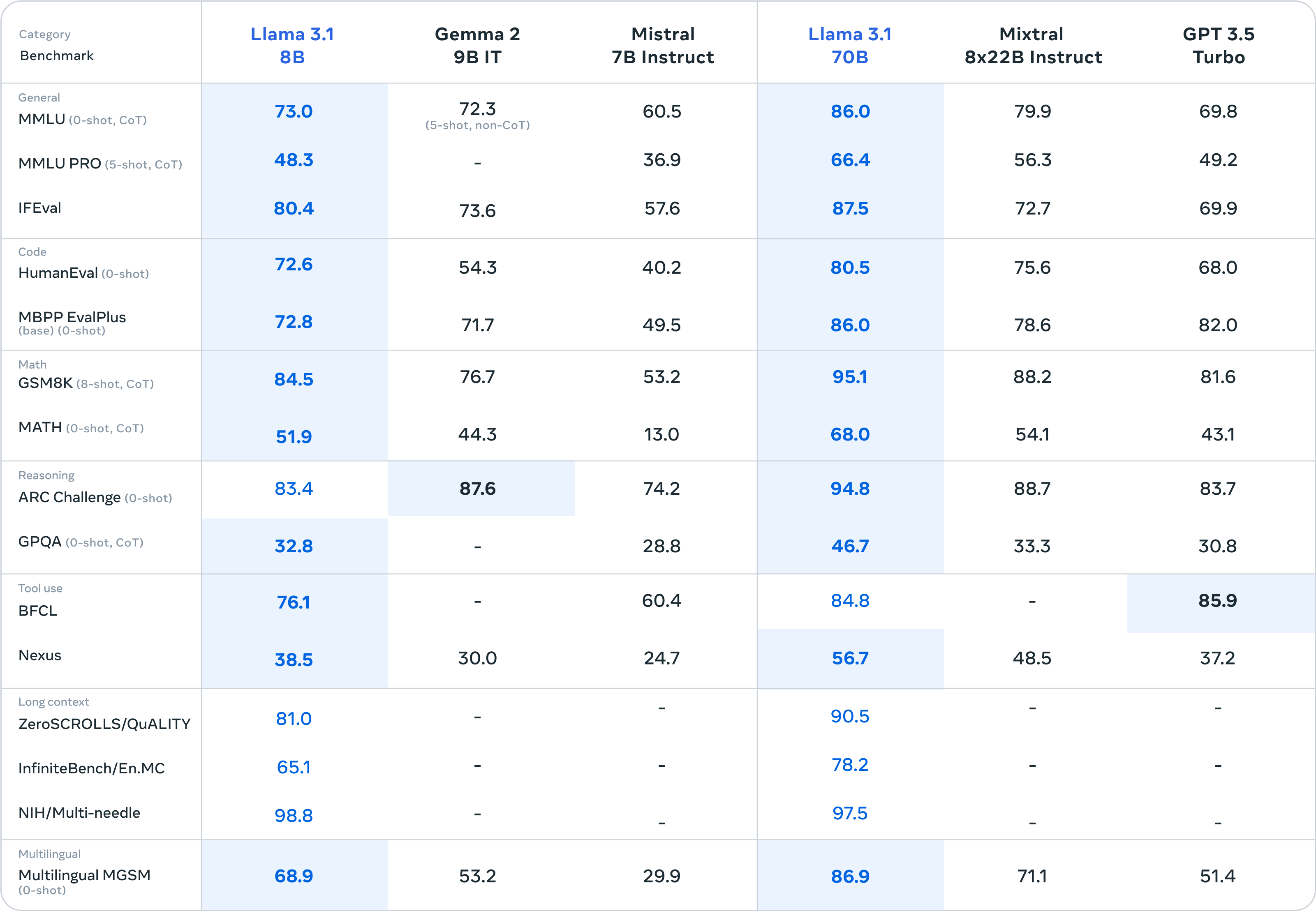
8B 和 70B 模型:小尺寸,高效能
Llama 3.1 8B 模型在各項表現優於參數相近的 Gemma 2 9B IT 和 Mistral 7B Instruct。而 70B 模型的表現更是驚人,不僅勝過開源模型 Mixtral 8x22B,更在測試資料集分數上完全碾壓 GPT-3.5 Turbo。
Llama 3.1 知識蒸餾與 License 更新
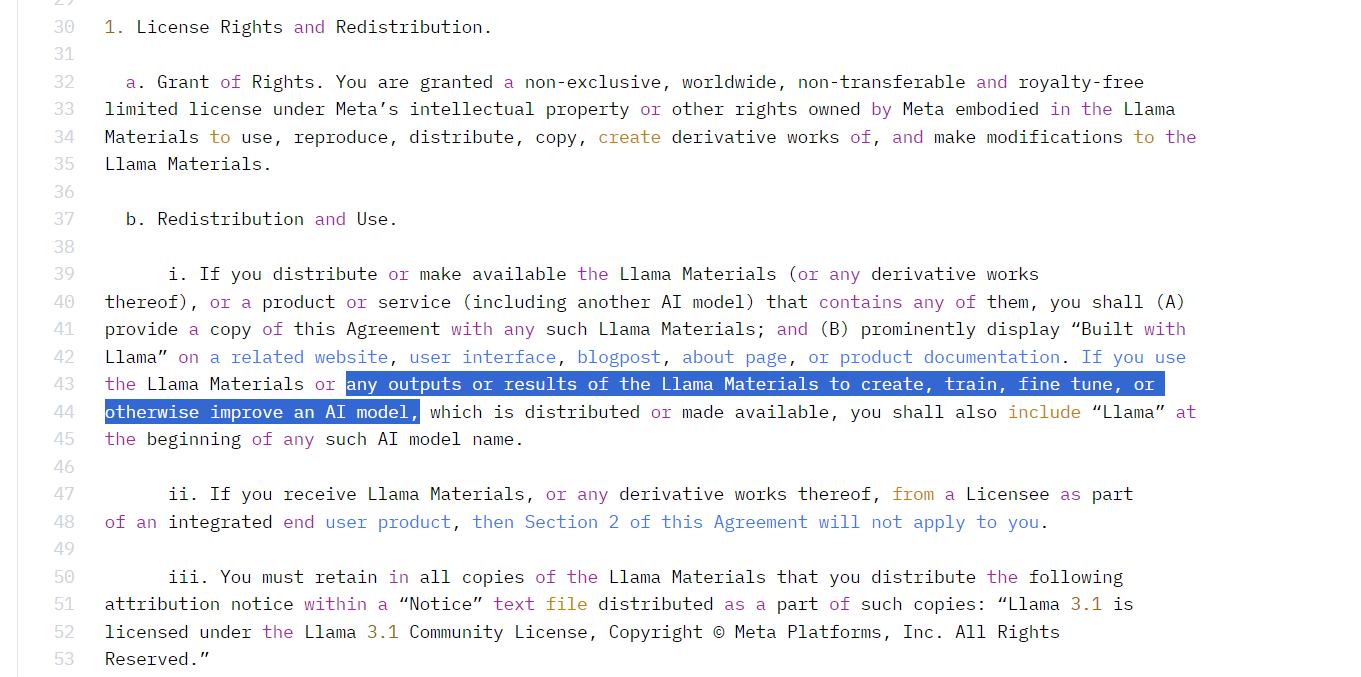
為讓大家使用 Llama 3.1 405B 模型進行知識蒸餾和生成合成數據,Meta 更新了 Llama 3.1 的 License。新版許可條款允許使用模型輸出改進其他語言模型,但訓練出的模型名稱開頭必須帶有 “Llama”,並在文件中標註 “Build with Llama”。
Llama 3.1 指令微調與 ipython 角色
Llama 3.1 發布了各個參數量的 Instruct 版本,也就是指令微調版本。Meta 表示,他們根據呼叫工具來微調 Llama 3.1 模型,並引入了一個名為 ipython 的新角色,用來接收和記錄呼叫完工具回傳的數據。
免費使用 Llama 3.1 模型
線上使用
-
Hugging Face HuggingChat: 免費使用 Llama 3.1 405B 和 70B 模型,提供友好的對話介面和工具調用功能。
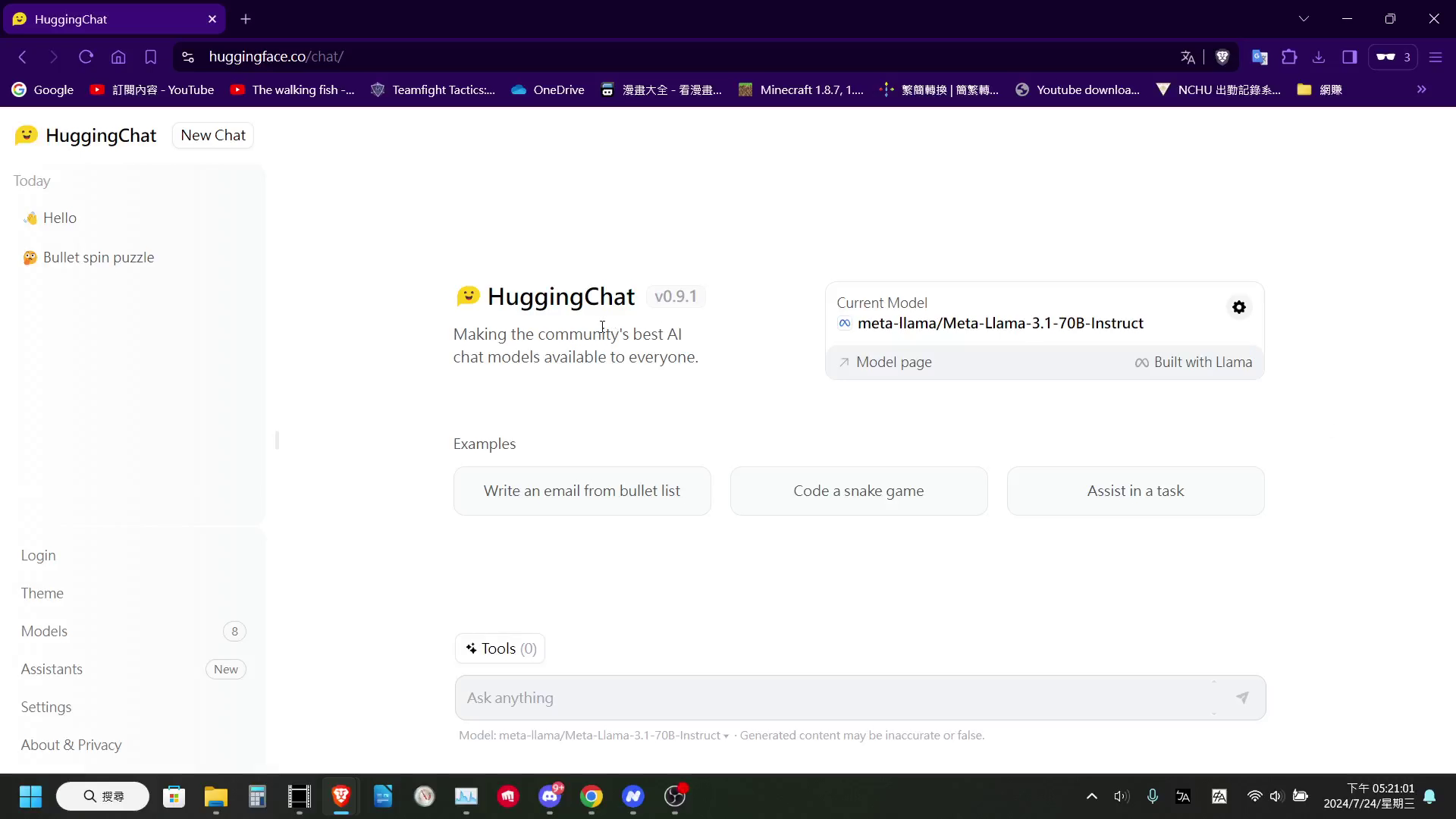
HuggingChat -
Groq: 使用自行研發的 LPU 進行推理,註冊簡單,生成速度快,支援免費 API 調用。
之前的介紹文章:
http://the-walking-fish.com/p/groq/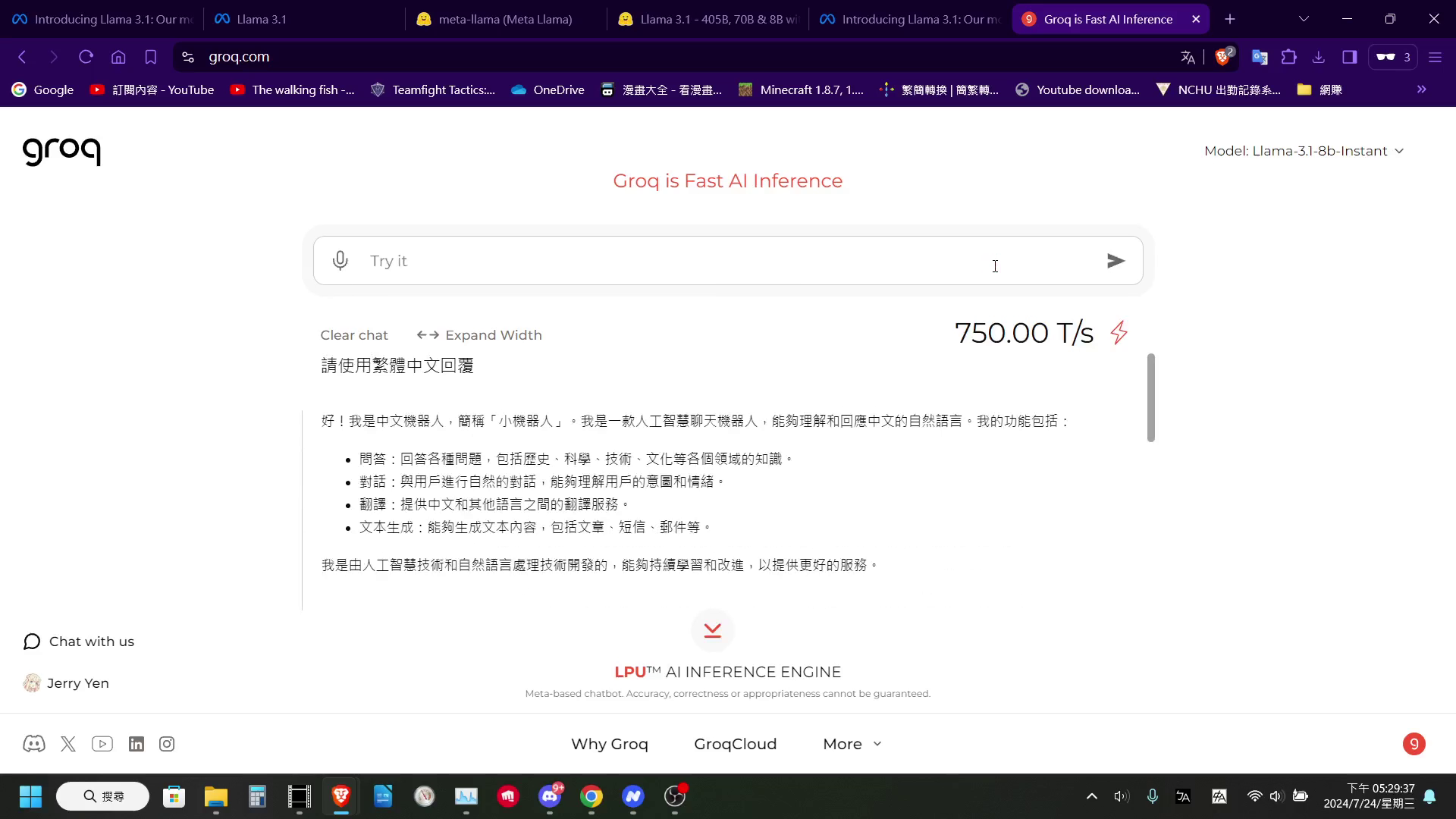
Groq


本機使用
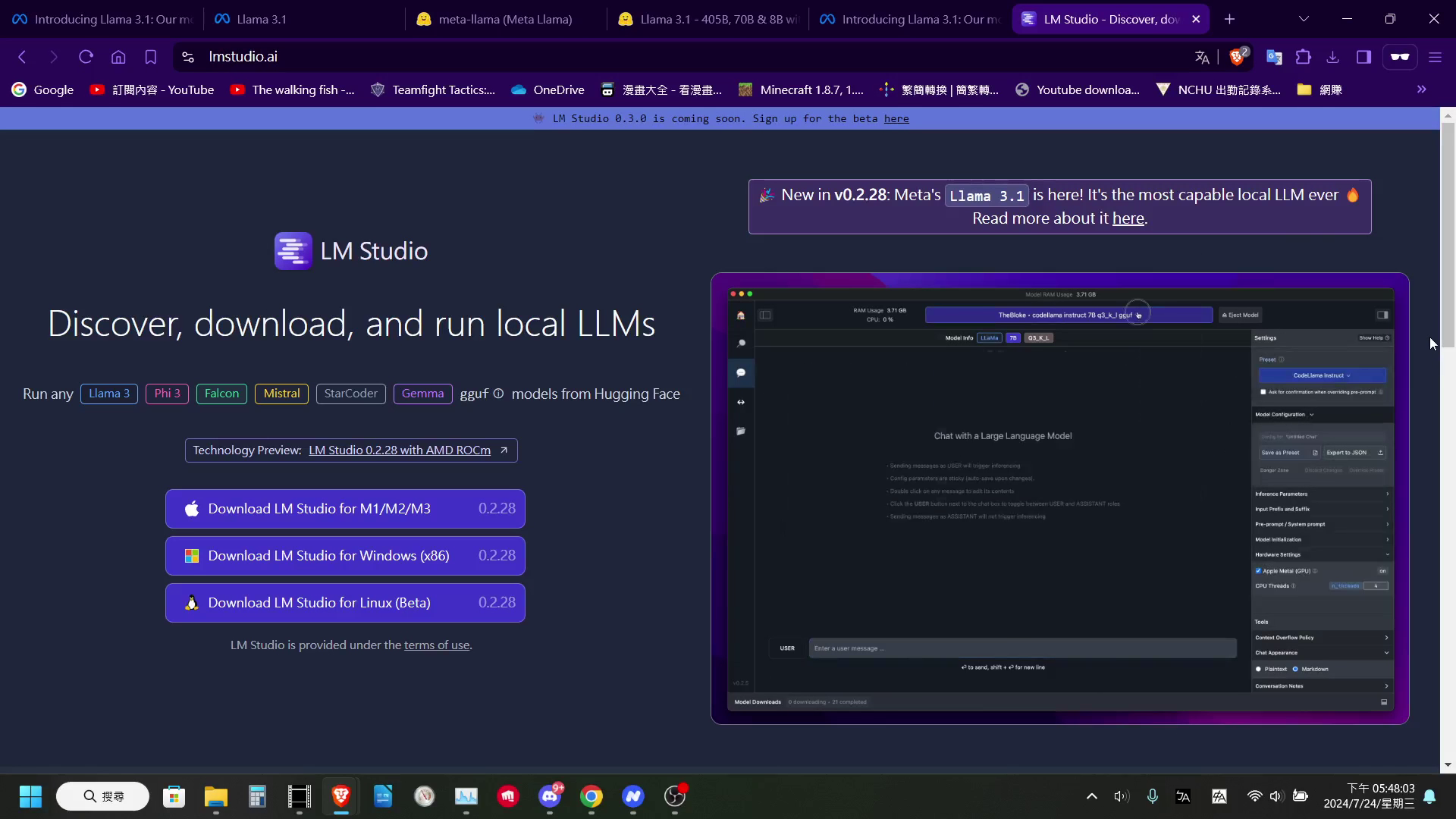
使用 LM Studio 程式下載和運行 Llama 3.1 模型。LM Studio 提供方便的模型下載介面、對話視窗,並使用 llama.cpp 進行模型推理,即使沒有獨立顯卡也能運行。
結語
Llama 3.1 的發布,特別是 405B 參數模型的強勁效能以及知識蒸餾的開放,可以說是開源語言模型推到了一個新的高度。也是近年來第一次,開源語言模型與閉源商業模型的表現如此接近。可見在的未來一段時間裡,Meta 的 Llama 系列模型,應該還會是開源語言模型開發的首選。
謝謝分享
😊