
現在各種大型語言模型可以說是百花齊放
大多數人的電腦硬體,也應該足夠跑動一些參數較少的語言模型了
但如果說要將這些開源的語言模型,實際應用在專案上,可能還是需要先經過一些微調
但是微調的方法並不是每個人都可以輕易掌握,對於大部分人來說應該會比較麻煩
而最近,我在 GitHub 上看到一個,用來微調語言模型的專案,名為 LLaMA-Factory,它裡面包含常見的各種微調方式,像是整個模型直接訓練微調,或使用 LoRa 來微調,在裡面都可以輕鬆做到
今天就來跟大家介紹一下
LLaMA-Factory 介紹
LLaMA-Factory 這個專案提供了一個方便的 WebUI 介面,並且整合了各種常見的訓練方式,讓使用者可以方便的調整參數便開始為條屬於自己的語言模型。
接下來,就讓我們來看看如何使用這個專案
硬體需求
在使用這個專案前,這邊還是要讓大家知道一下,要 Fine Tune 一個模型需要的基本硬體需求
這邊作者有提供一個不同的參數量,大約會需要多少的 VRAM,才能 Fine Tune 的一張表
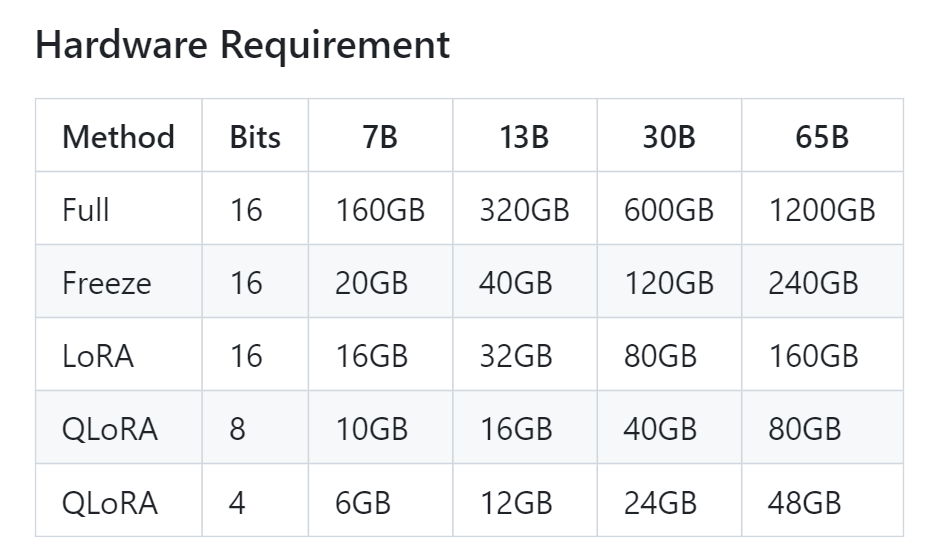
我們可以看到 7B 參數的模型,即便開啟 4bit 量化,使用 QLoRa 來 Fine Tune,也會需要 6GB 的 VRAM,13B 參數的模型更是要吃到 12GB 的 VRAM。基本上想要玩語言模型微調,可能還是得要有張稍微好一點的顯卡。
Colab 限制
看到這張 VRAM 需求的表格後,許多人可能會想到是否可以使用 Colab 來進行訓練
但這邊我要很可惜的告訴大家,算是一半做得到一半做不到
我們確實可以在 Colab 裡面載入 7B 以上的模型,也確實可以進行訓練
但是在導出的時候,可能是因為 LLaMA-Factory 的輸出,會將 LoRa 層壓進模型內,這個步驟會需要將整個模型載入到記憶體
而免費版的 Colab 僅有提供 12GB 左右的系統記憶體,所以基本上在最後輸出的步驟,一定會報錯(付費版有更多記憶體所以應該沒差)
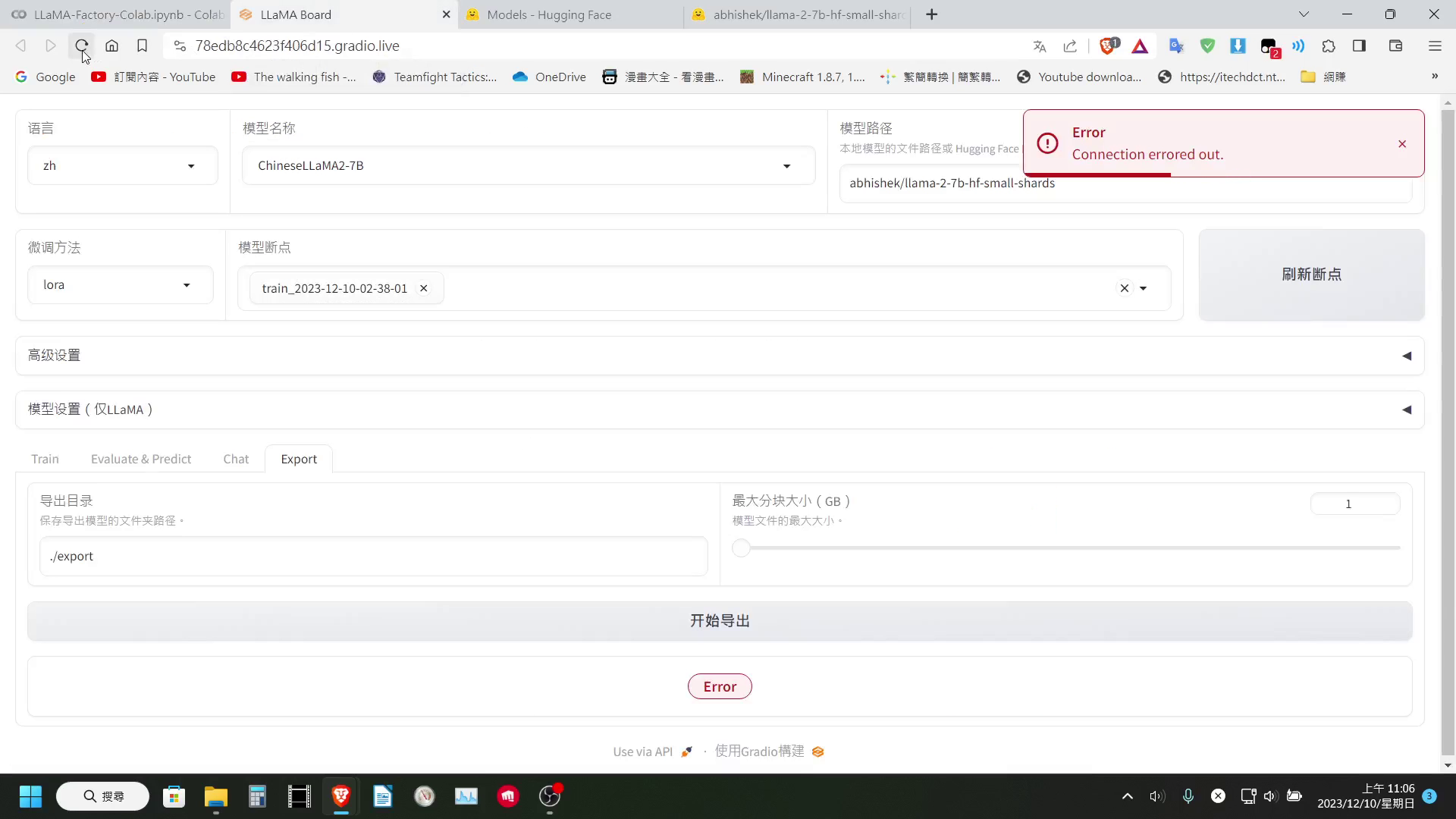
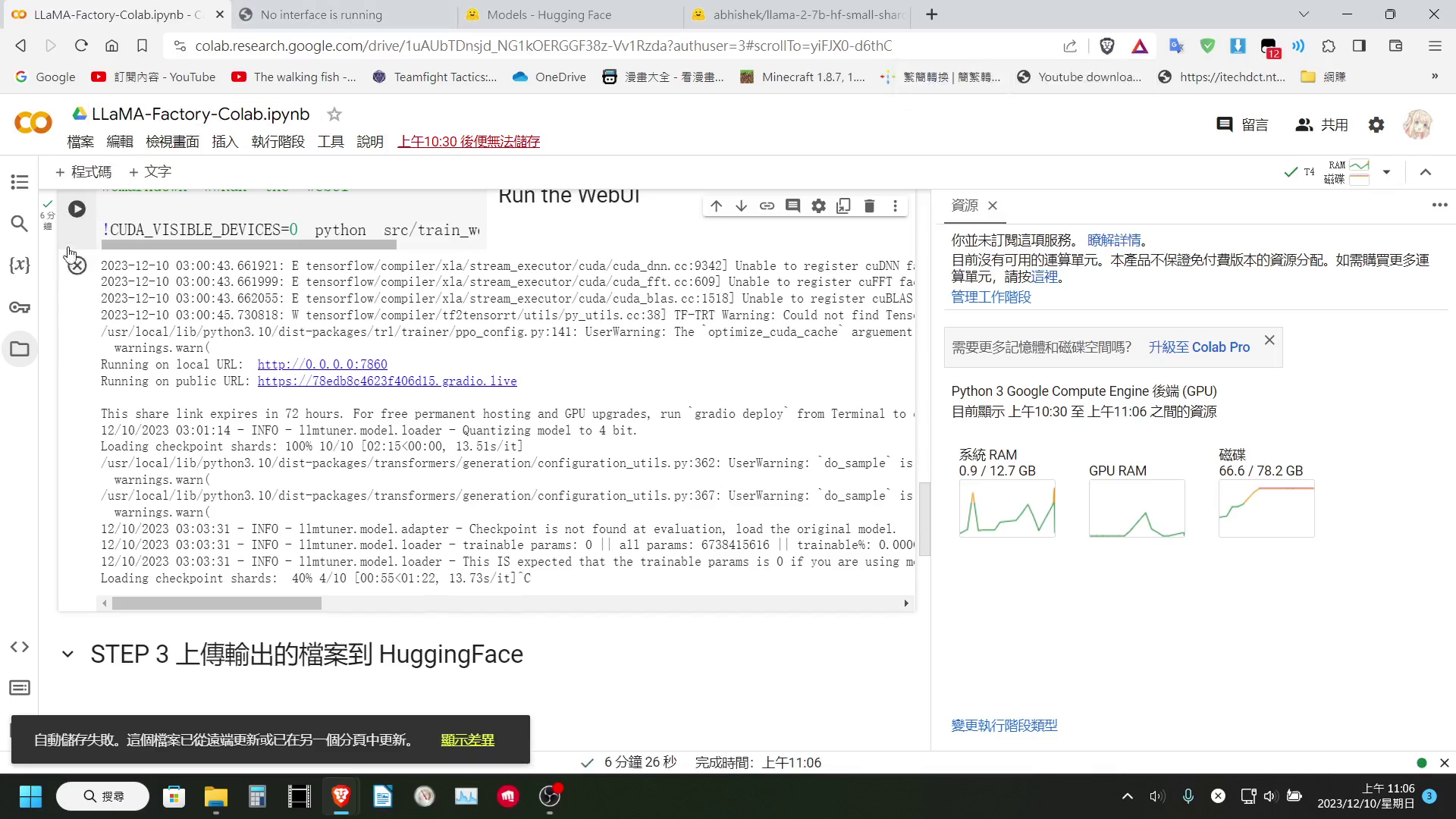
要說可以的部分,當然是在訓練的時候,它也會將 LoRa 層獨立保存下來,所以其實我們也可以直接把 LoRa 層下載下來,也一樣是可以使用
所以我還是有簡單的做個 Colab 記事本,讓大家可以方便使用 Colab 進行訓練
LLaMA-Factory使用教學
那麼接下來,就讓我們從如何在本機上安裝這個專案,開始說起
本機安裝
首先要在本機上安裝這個專案,我們需要先將這個專案下載下來,然後解壓縮
接著我們需要創建一個虛擬環境,並將它開啟
|
|
接下來安裝 PyTorch、requirements.txt 等必要套件。
之所以將 PyTorch 獨立出來安裝,是因為如果不加上後面的指定版本以及 --extra-index-url,可能會安裝到只能使用 CPU 版的 PyTorch。
|
|
如果不小心安裝了只有 CPU 版的 PyTorch,我們可以先將他解安裝,然後清除快取後再重新安裝一次即可:
|
|
最後則是 bitsandbytes 函式庫,Windows 系統上需要安裝預編譯的函式庫。如果是 Linux 系統,則是只需要輸入 pip install bitsandbytes>=0.39.0 即可
|
|
啟動 Web UI
安裝完成後,我們就可以啟動 LLaMA Factory 的 Web UI 介面,我們輸入以下指令:
|
|
稍等一下,WebUI 就會自動打開(如果未開啟可以在瀏覽器手動輸入 localhost:7860)
到了這一步,我們其實已經可以開始訓練了,但是要把語言模型微調成自己想要的樣子,我們現在還缺一項東西,就是 訓練資料集。
導入訓練資料集
作者在專案的 data 資料夾內有提供資料集的格式,我們需要按照這個格式,才能讓我們自己準備的訓練資料,能夠被用來訓練。
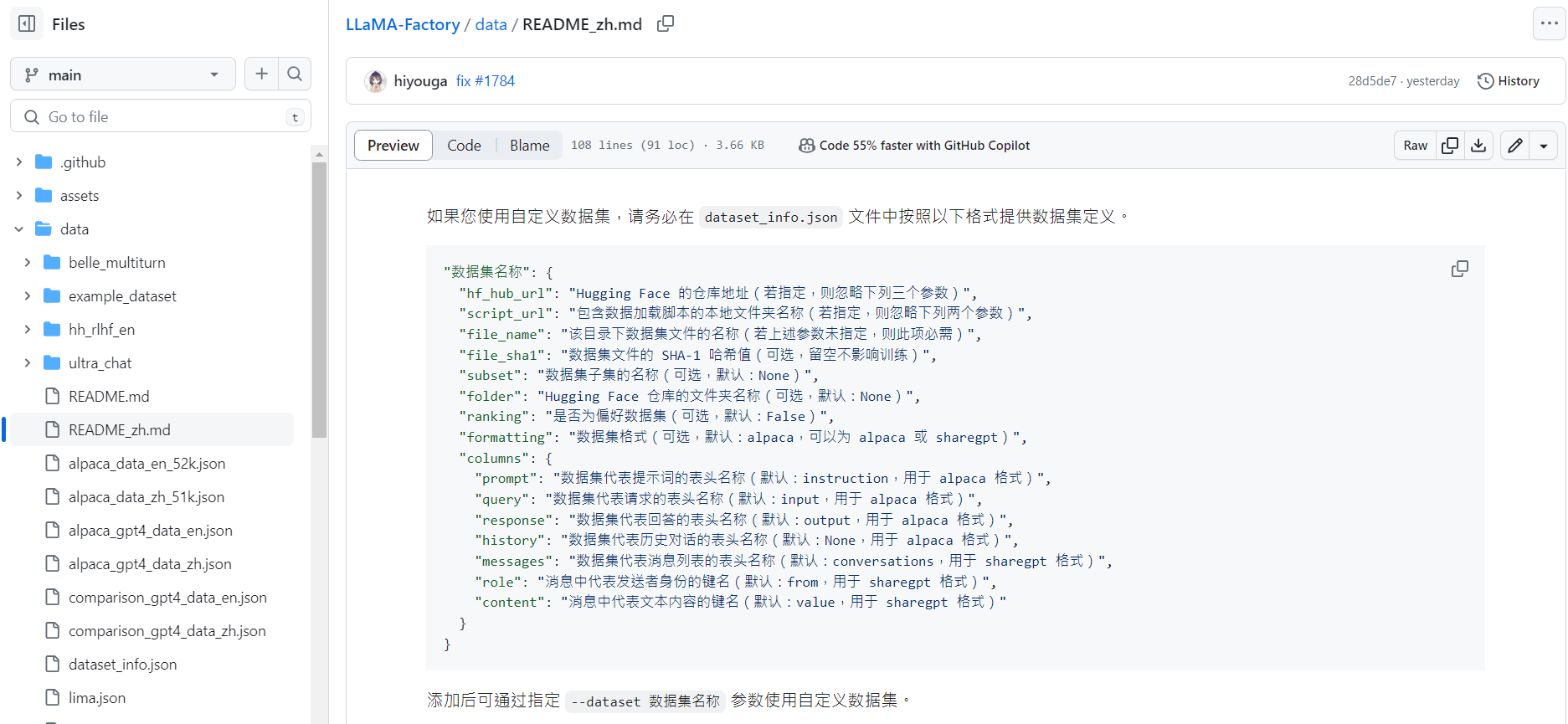
以下簡單跟大家介紹 2 種數據集的導入方式
數據集導入方式1 - JSON檔
在專案的 data 資料夾內,有內建一些資料集,我們可以根據這些資料及的 JSON 檔,來製作屬於自己的資料集。
以下是製作 JSON 資料集的格式:
|
|
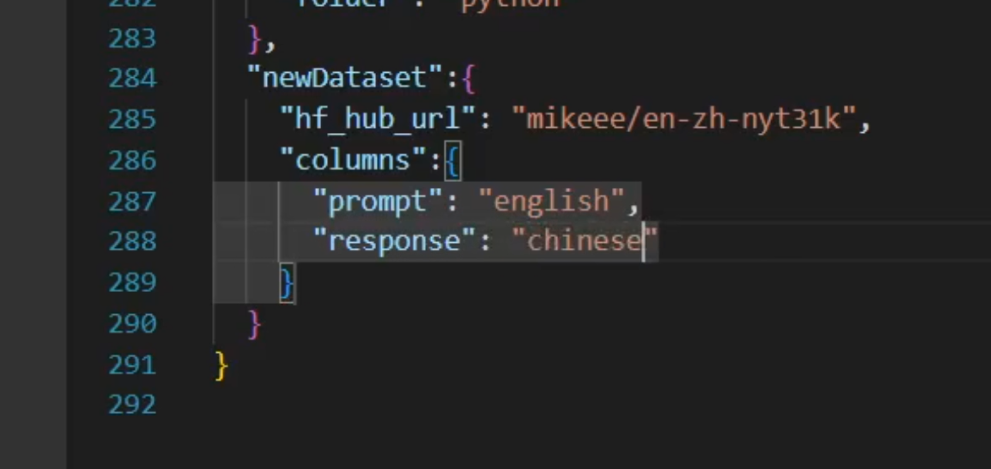
在製作玩 JSON 資料集後,我們需要在 dataset_info.json 裡面填寫該資料集的欄位對應資料,它的格式如下:
|
|
數據集導入方式2 - 直接讀取 Hugging Face
除了製作 JSON 資料及外,LLaMA-Factory 還支援可以直接從 Hugging Face 上抓取資料集,我們只需要在 dataset_info.json 填入該資料集的 Hugging Face 路徑,以及資料集的欄位對應就可以。
它的格式如下:
|
|
調整參數開始訓練
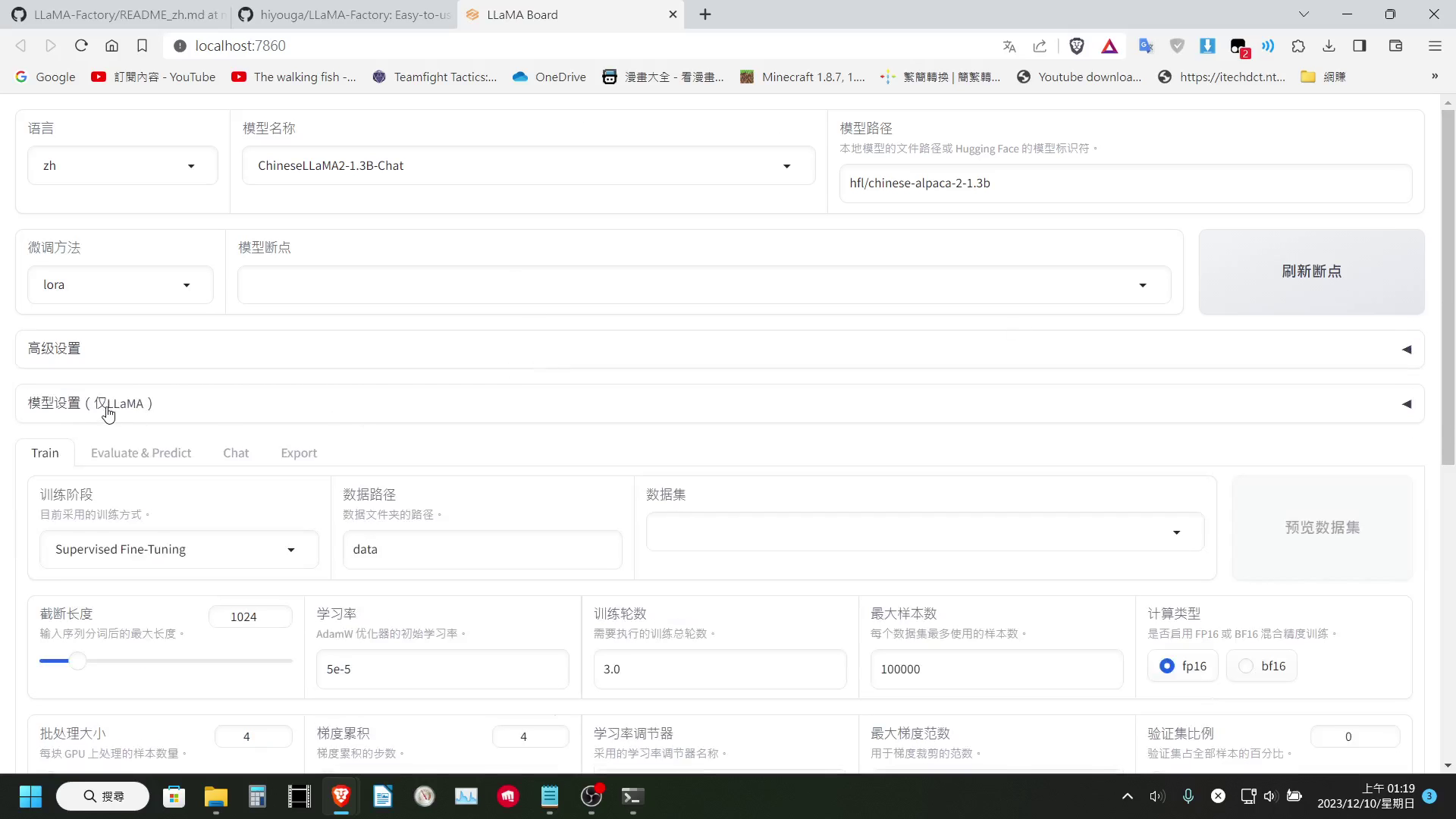
有了訓練資料集,我們就可以開始選擇要 Fine Tune 的模型,設定各種參數。
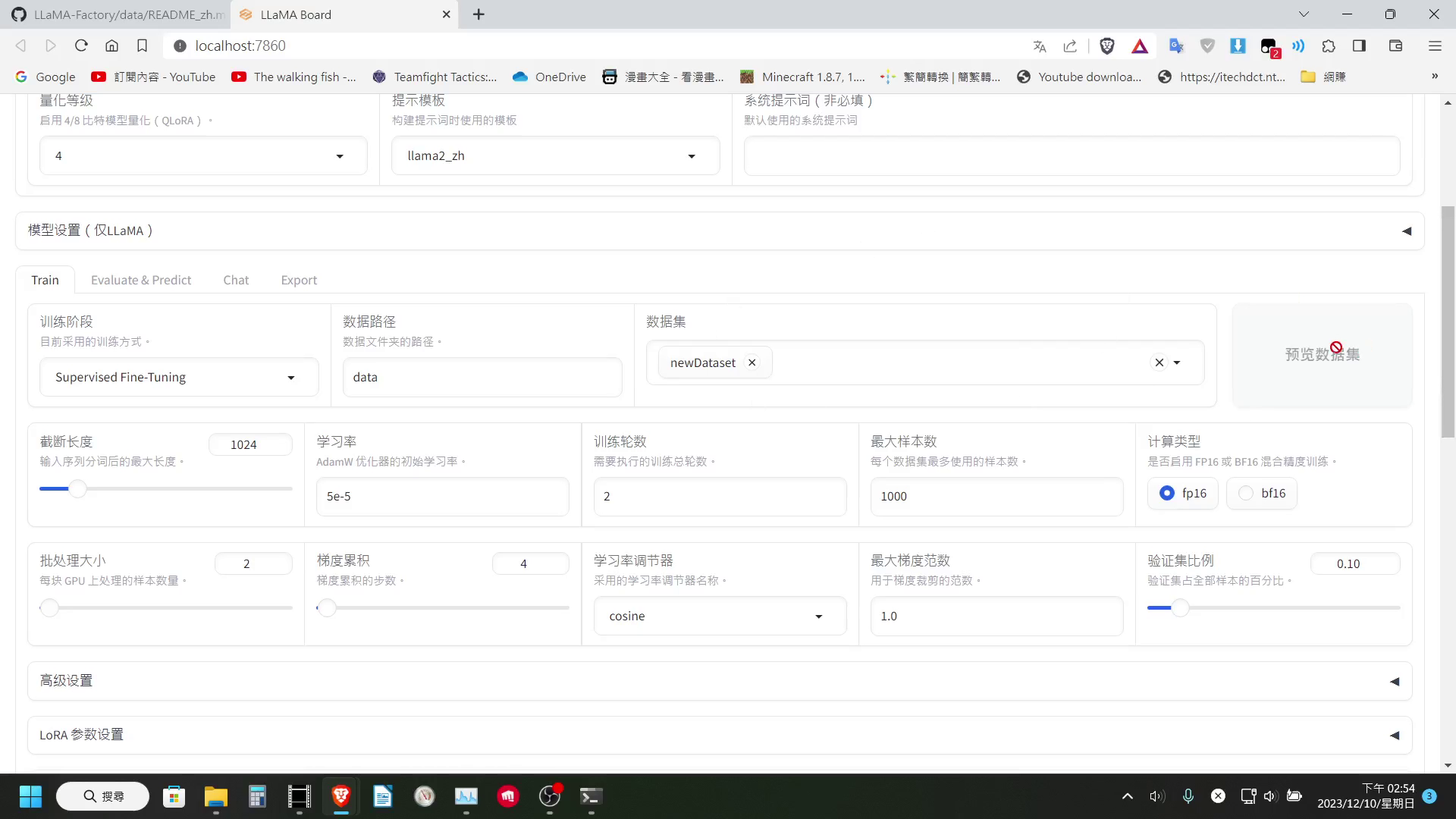
像我這邊就可以設定 4bit 量化來節省 VRAM,然後如果只是要微調對話,選擇「監督式微調」的訓練方式即可
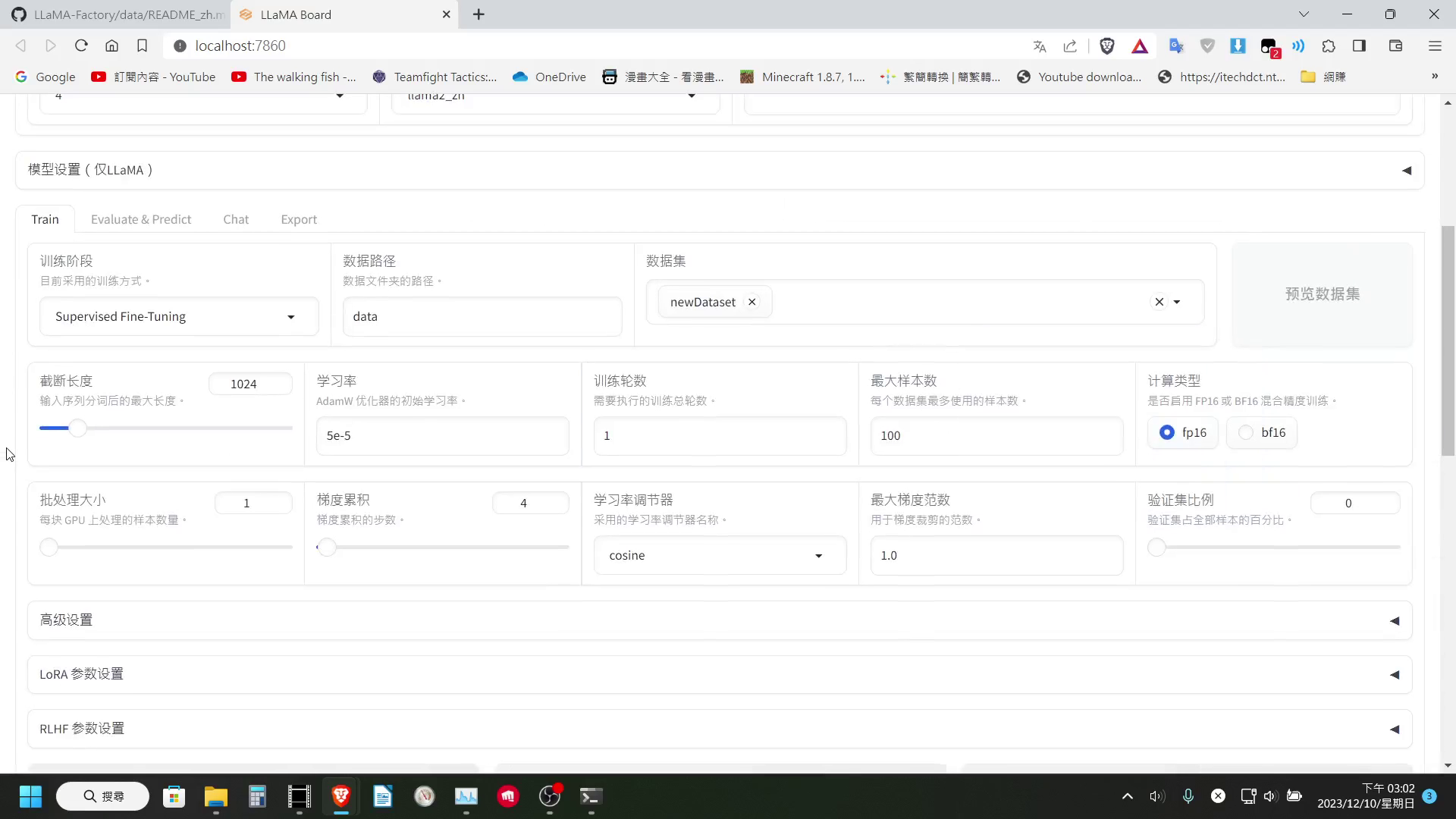
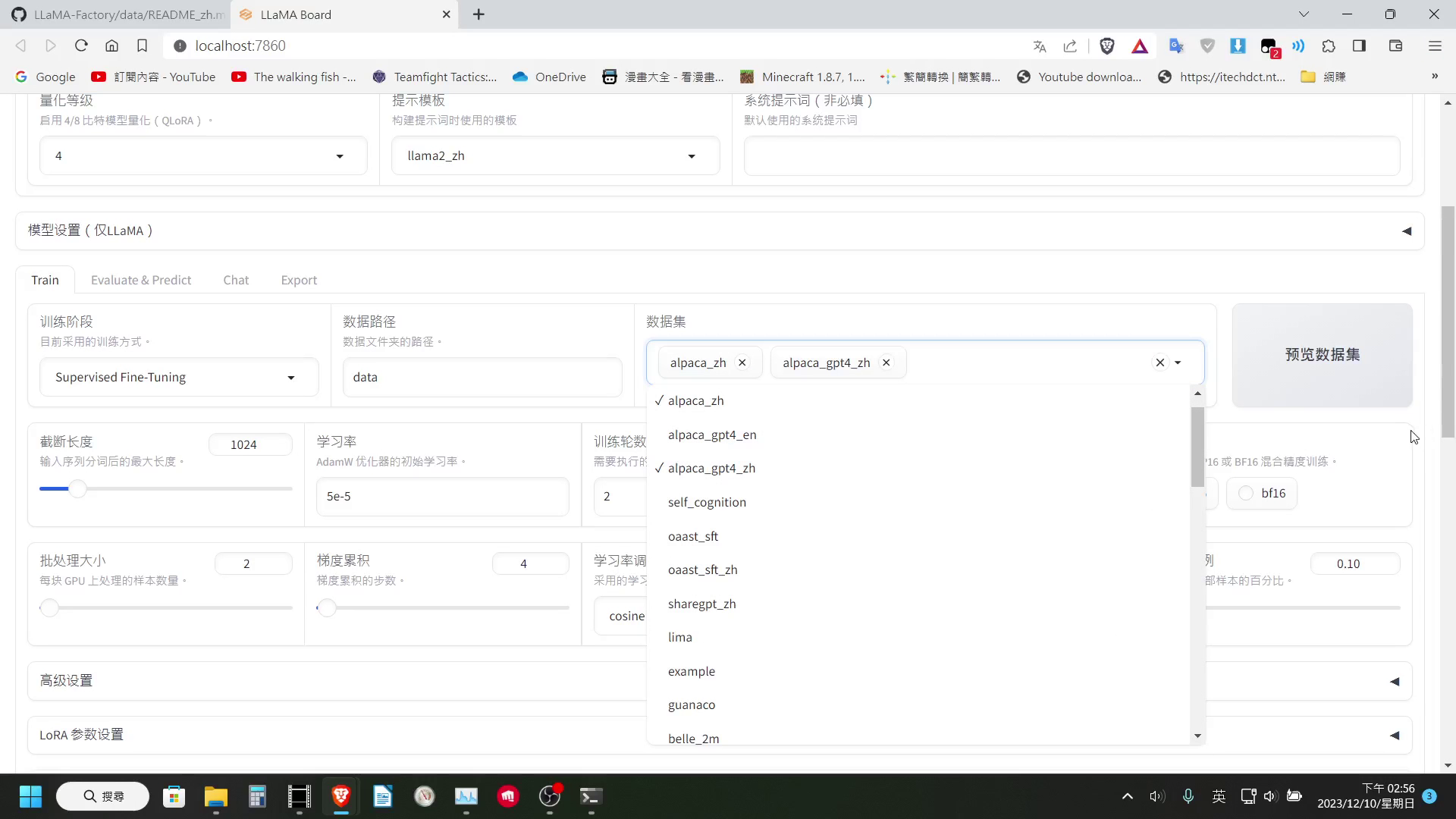
資料集的部分這邊還有一點可以注意一下,就是 LLaMA-Factory 是支援可以同時選擇多個資料集一起訓練的,下方設定的最大樣本數設定,是每個資料集最多使用的樣本數。
同時如果是使用 JSON 檔來做為資料集,那麼在 WebUI 裡我們可以簡單的預覽一下訓練資料。但如果是使用 HF 上的資料集,便無法預覽,這邊可以稍微留意一下。
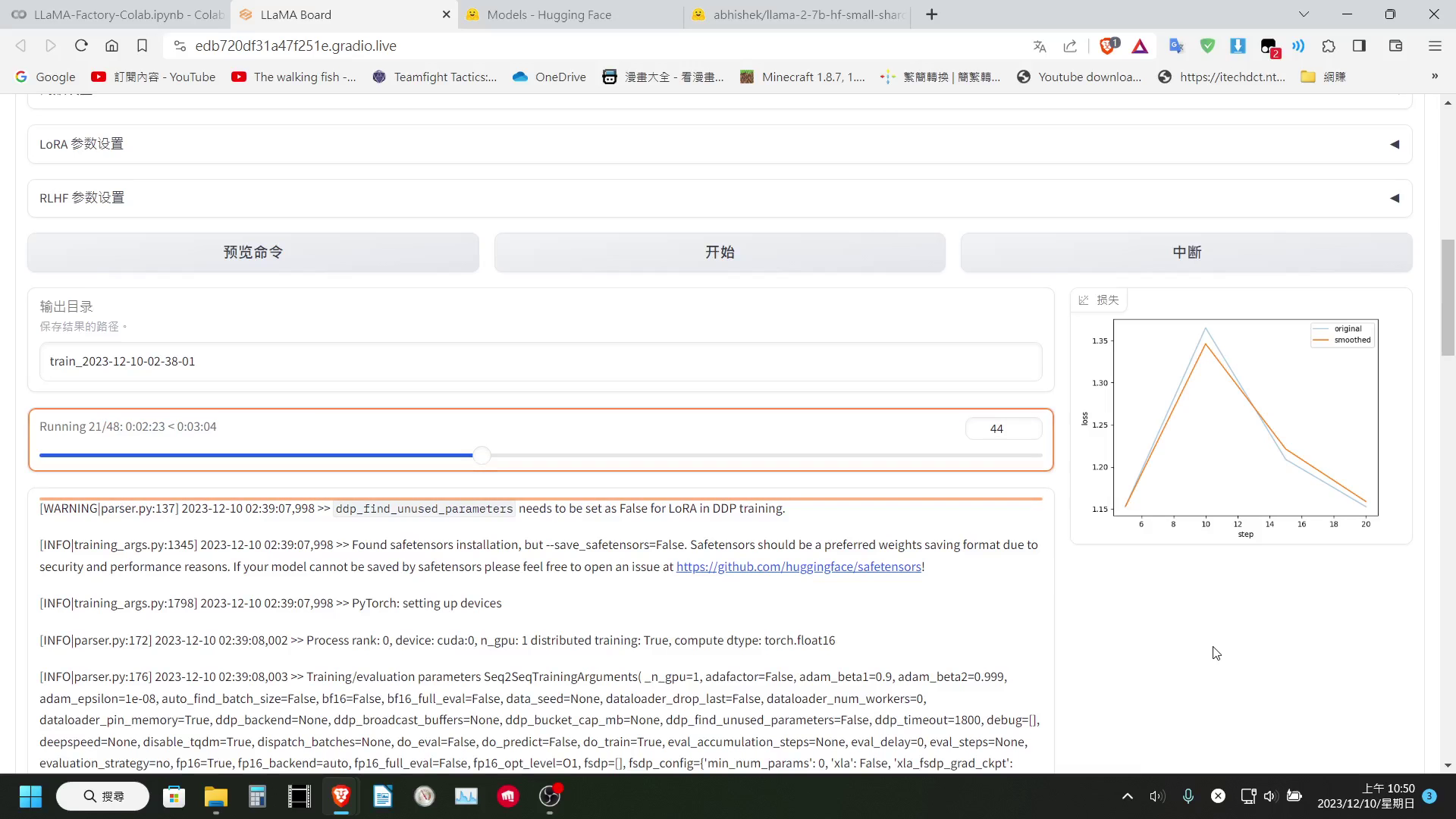
設定好參數後我們就可以按下開始訓練「開始訓練」
測試微調好的模型
等到模型訓練完成,我們可以在「Chat」分頁中測試效果
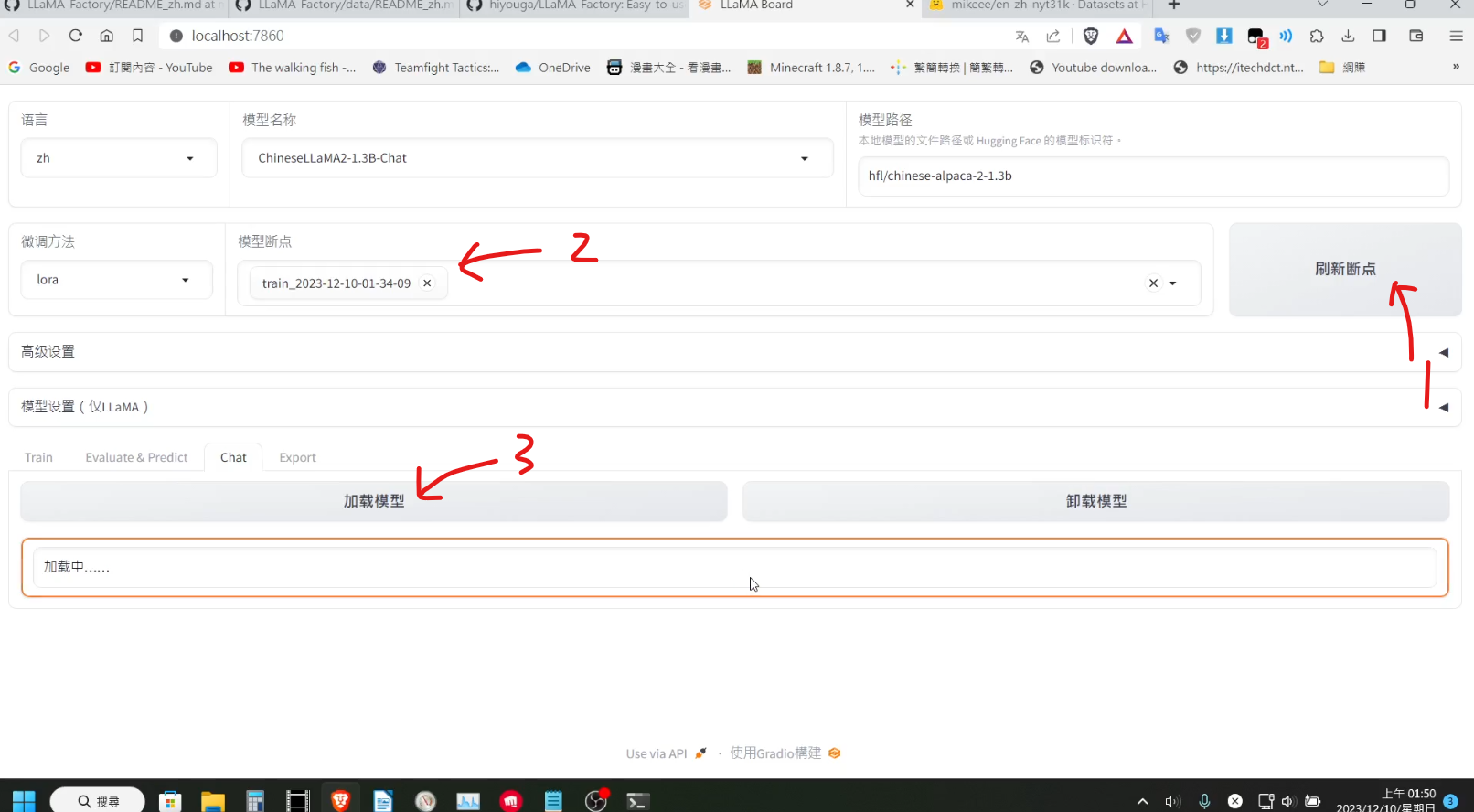
切換到該分頁後,我們在上方刷新一下 checkpoint 的列表,選擇剛剛訓練的 checkpoint,在點擊下方的加載模型,稍等一下下方就會出現聊天框讓我們測試。
導出模型
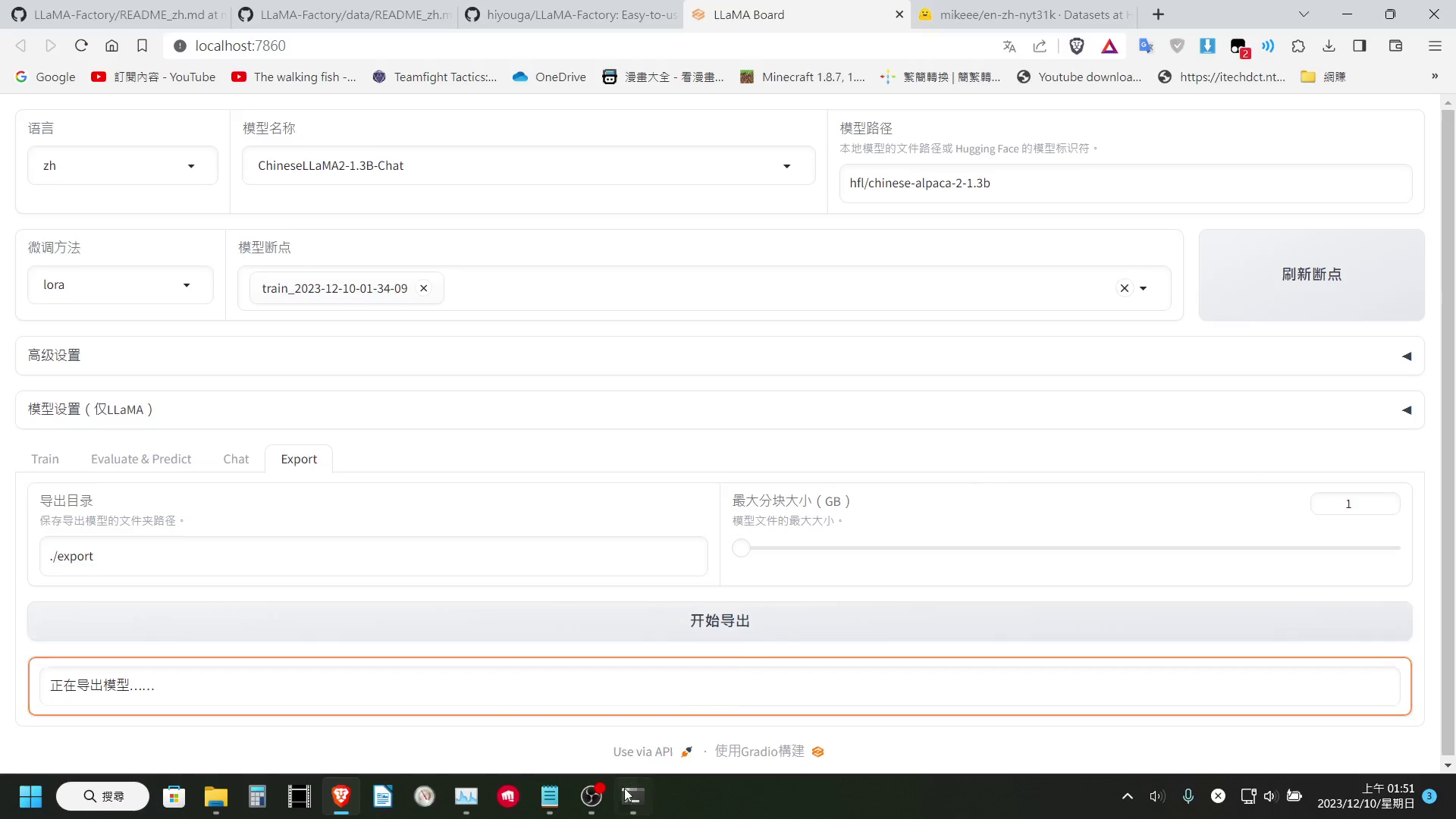
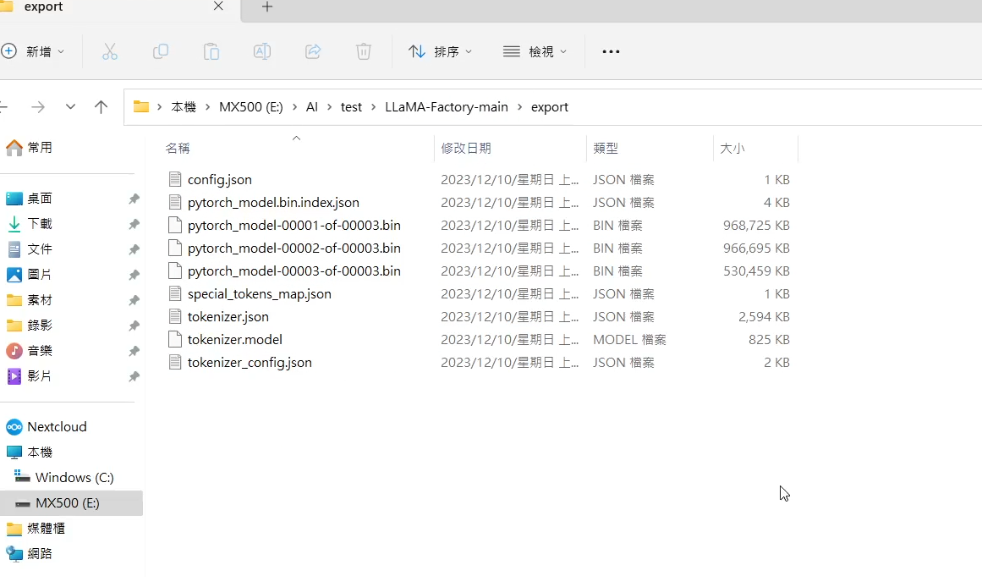
如果經過測試覺得結果滿意的話,便可以導出模型,切換到export的分頁後,我們可以設定模型要導出到哪個資料夾內,也可以設定模型要以多大的大小分塊。
這邊基本上不太需要去調整,只要填好導出模型的資料夾即可按開始導出,稍等一下就可以在填寫的導出資料夾中看到道出的模型了!
在 Colab 使用
這邊我有簡單的做個 Colab 記事本,讓大家可以方便使用 Colab 進行訓練
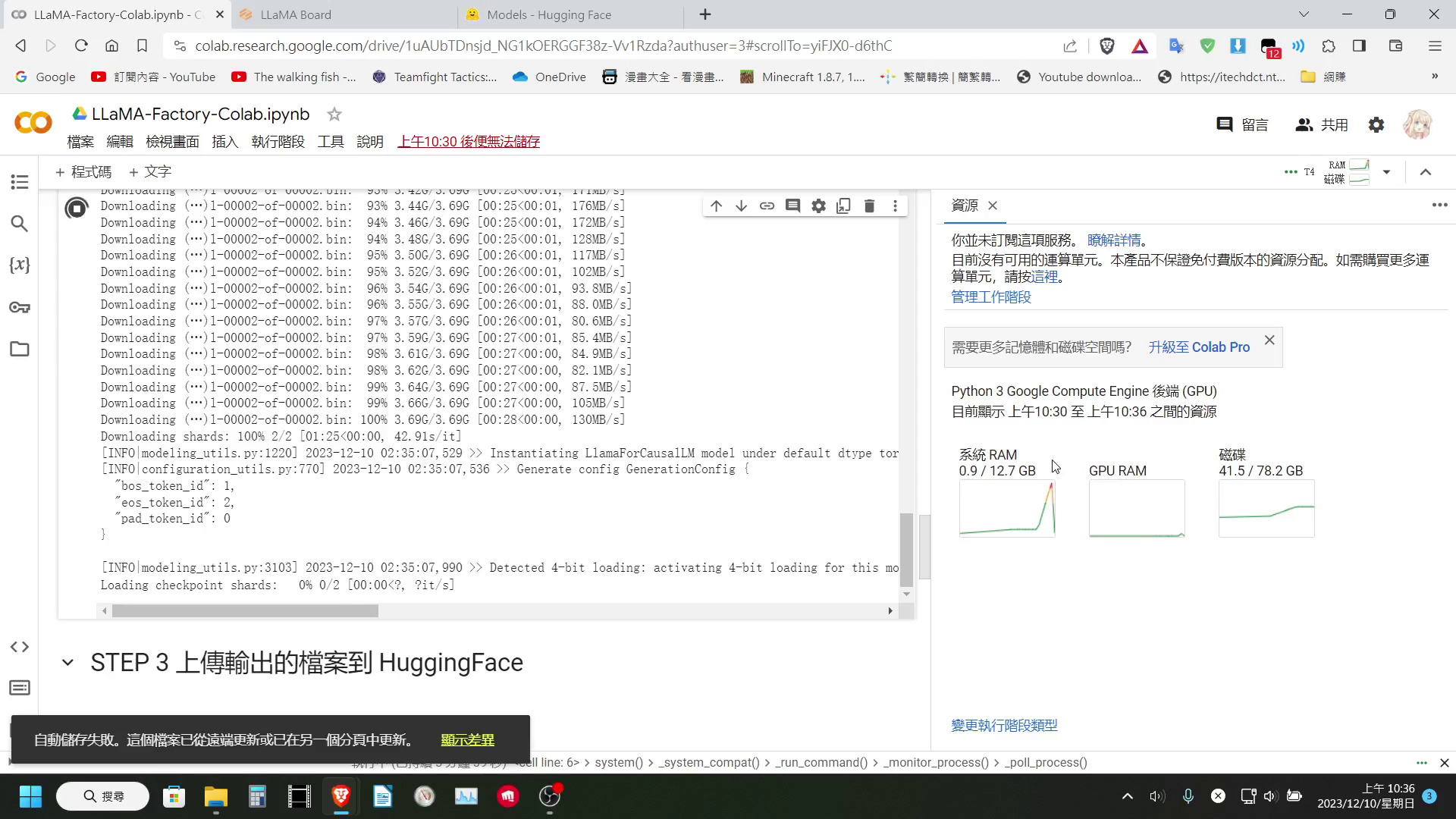
!!!這邊要提醒大家一點!!!,如果使用 Colab 免費版,直接使用預設的 Hugging Face 路徑載入 7B 以上的模型,基本上一定會爆系統記憶體。
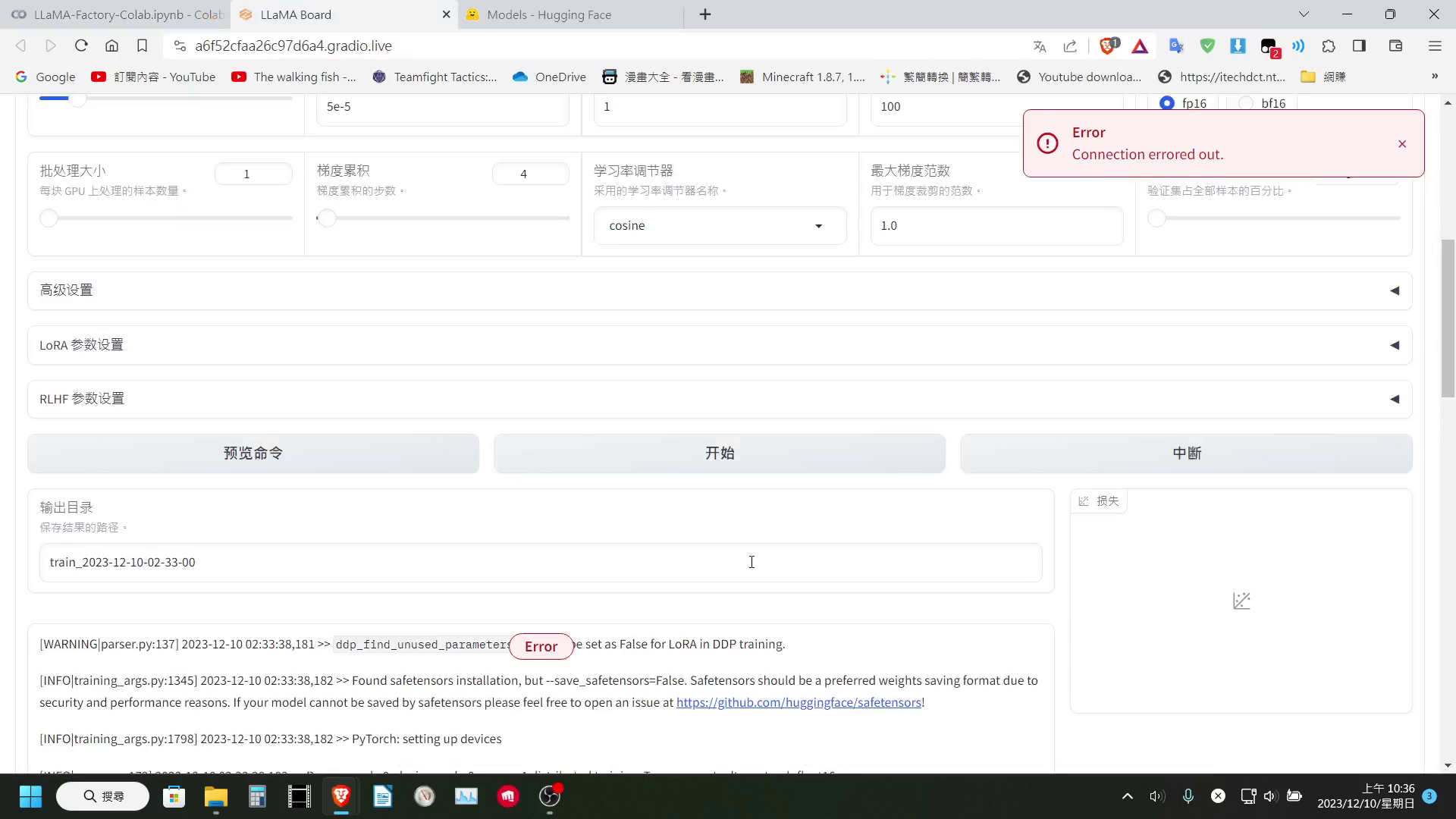
所以我們需要在 Hugging Face 上找一下,有沒有分成更多 Shard 版本的該模型,將其路徑複製下來替換預設的模型下載路徑。
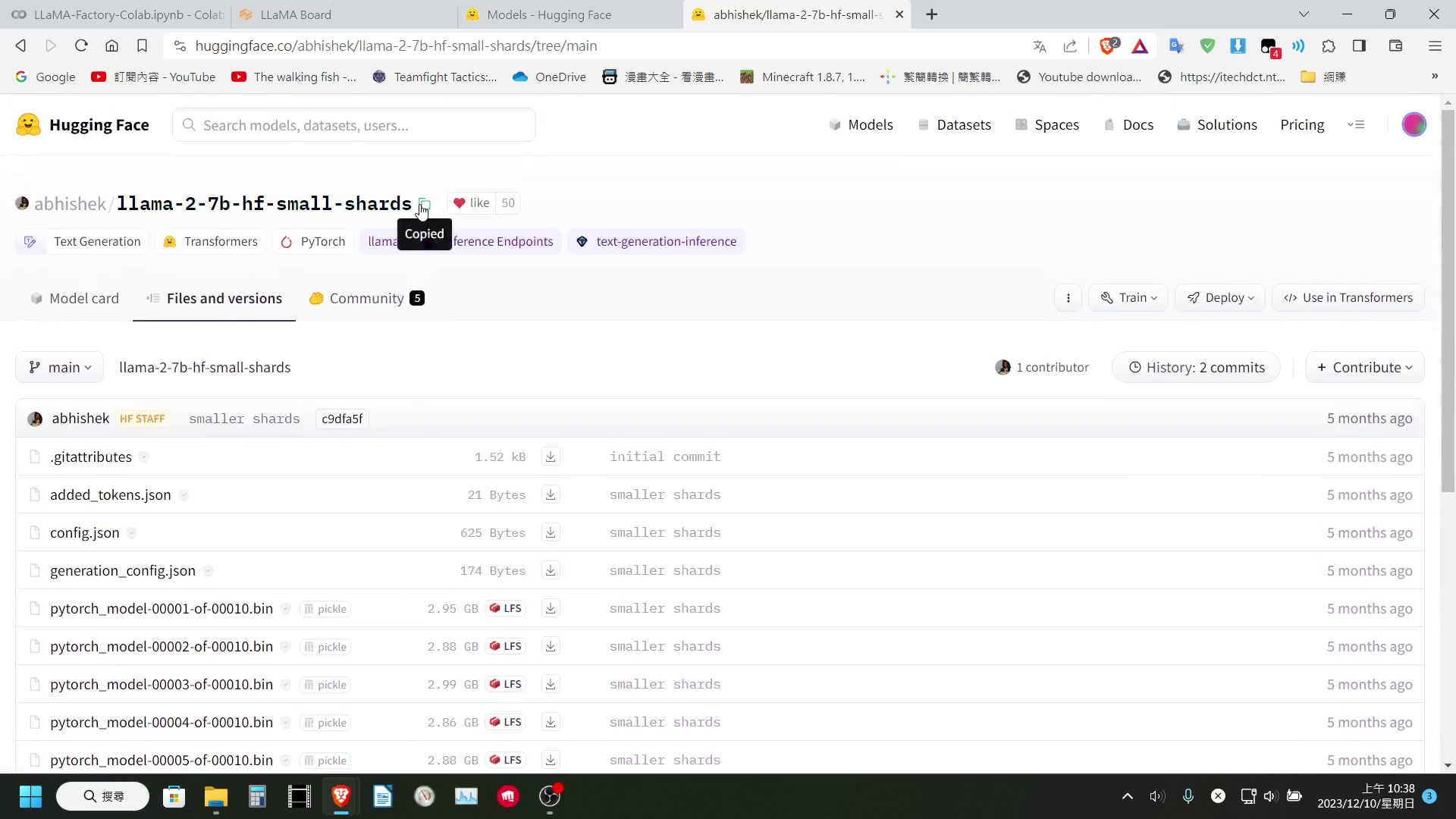
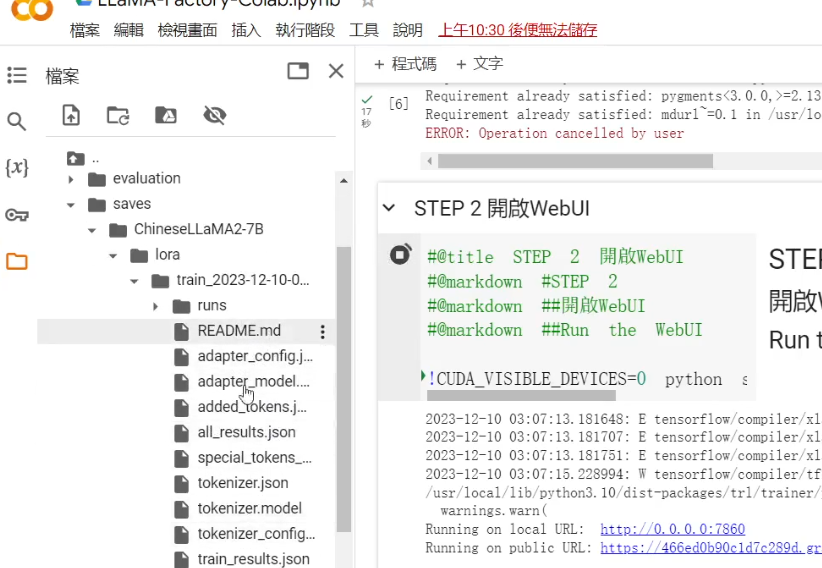
至於輸出的部分,目前我是無能為力,因為 LLaMA-Factory 在導出時,會合併 LoRa 權重,這個步驟會需要將整個模型載入到記憶體中,所以免費版的 Colab 基本上一定會爆系統記憶體。
我們能做的,就只有只保存 LoRa 權重了,因為每次的訓練,LLaMA-Factory 都會在 saves 資料夾中的基底模型名稱的資料夾內,新增一個資料夾,裡面儲存著該次訓練的 LoRa 權重,所以如果使用 Colab 免費版訓練,我們只能選擇保存 LoRa 權重了。
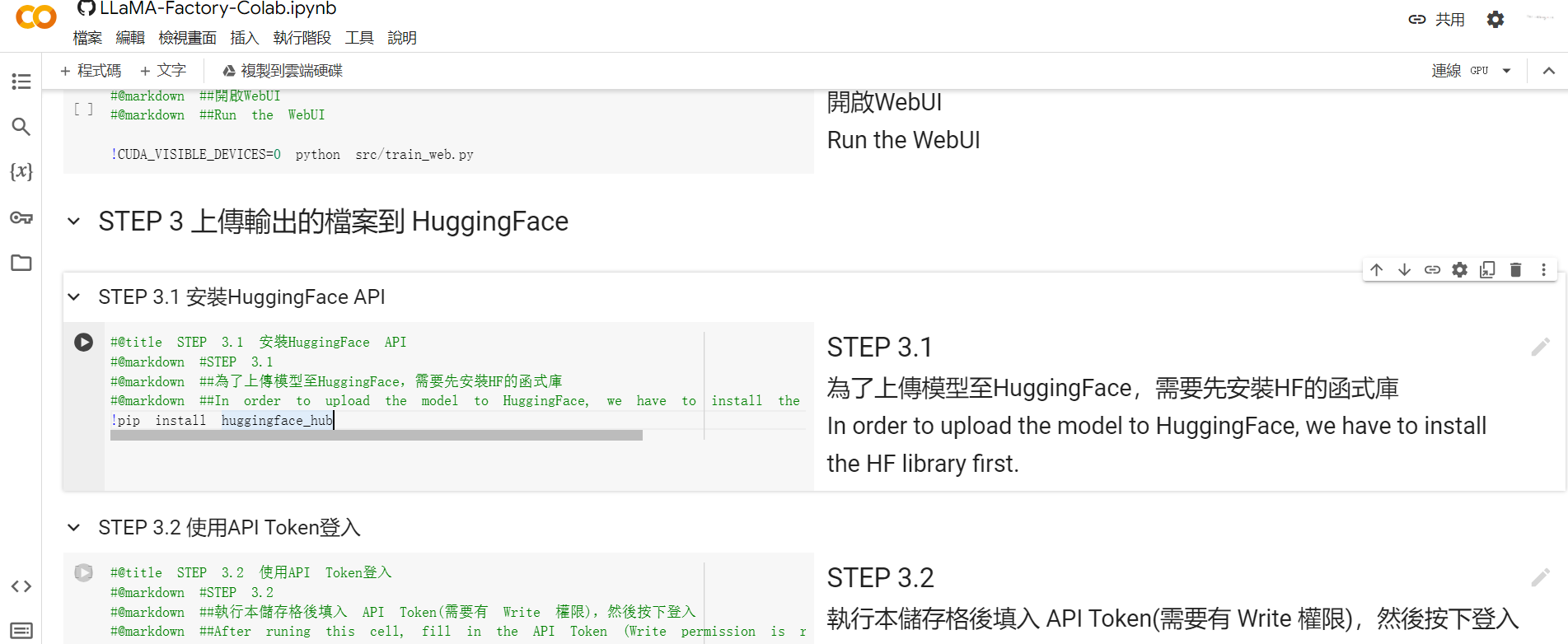
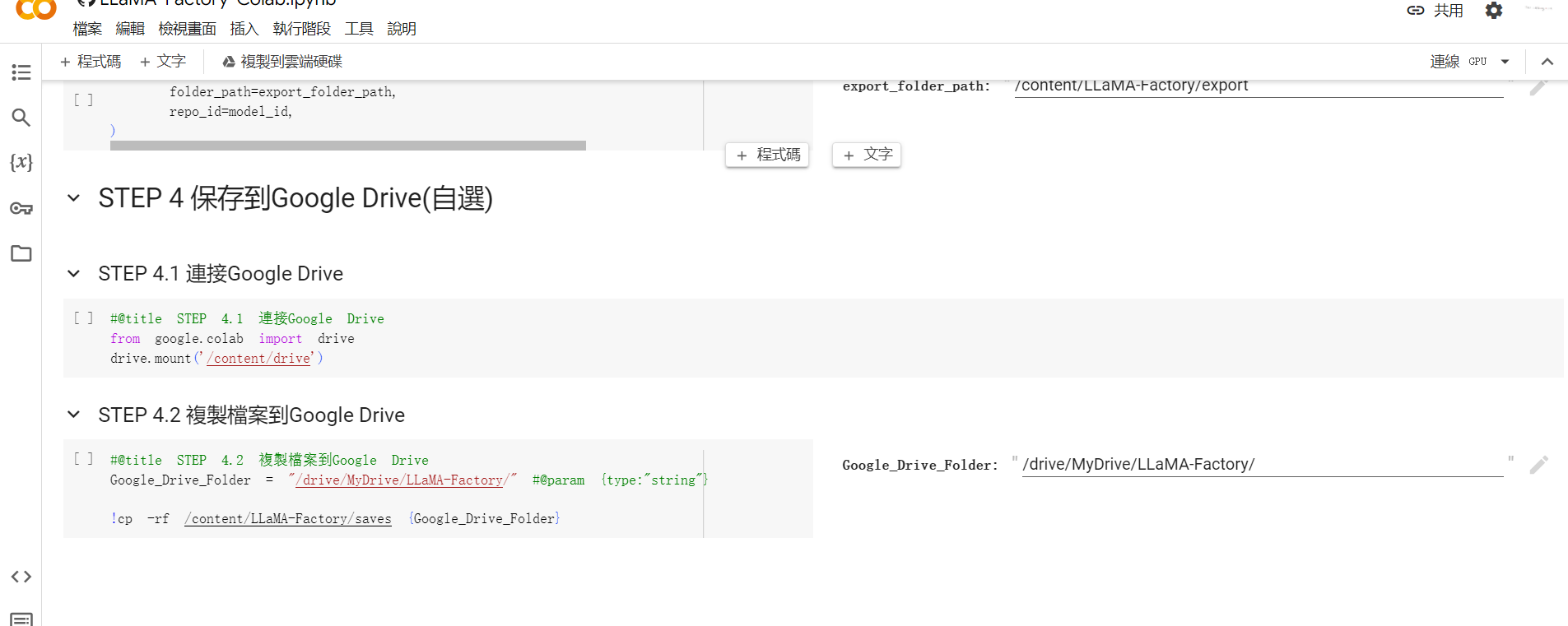
這邊我有簡單的製作了 2 個程式區塊,讓大家可以選擇是要將模型上傳到 Hugging Face 上,亦或是存到 Google Drive 內。至於要用哪個大家可以自行選擇
提醒一下
如果要上傳到 Hugging Face 的話,需要有一個具有 Write 權限的 Hugging Face Token。
結語
LLaMA-Factory 提供了非常便利的介面,讓我們可以很輕鬆的對大型語言模型進行客製化微調
如果大家對於微調自己的語言模型有興趣,或是有想要依據此製作的專案的話,LLaMA-Factory 應該會是一個相當方便的工具!
(P.S.如果文中有任何地方錯誤,歡迎指正,我會盡速修改)


作者你好,想請教兩個問題,從文章看起來是會先下載專案下來,之後就可以用程式碼運作,這樣是不是代表說,我安裝下來後,就可以直接離線建立模型?(有資料洩漏考量想用離線)
另外,因為我目標訓練集不大,excel檔案可能才幾MB,照理來說應該文書機是可以訓練模型的? 如果理解有什麼錯誤還請指教~
感謝您!
可以直接對存在本地端的模型進行訓練, 我就是用llama factory來微調TAIDE. 但如果是想要用文書機(我假定是8GB VRAM)來訓練模型, 還是不建議. 而且, 如果用太少量的資料集訓練, 是無法把預訓練模型變成你想要的樣子的.